本复习资料不以讲解为目的,建议勿以此为学习资料。
李小舟老师的总结思维导图,做得太好了,放在这里作为开头。
这里 可以下载PDF版本
基本概念
几个性质
线性方程组
A x = b Ax = b A x = b
基本概念
向量范数:非负、齐次、正定、三角不等式p p p ∥ x ∥ p = ( ∑ i = 1 n ∣ x i ∣ p ) 1 p \| x\|_{p} = \left( \sum_{i = 1}^{n}|x_{i}|^{p}
\right)^{\frac{1}{p}} ∥ x ∥ p = ( ∑ i = 1 n ∣ x i ∣ p ) p 1 ( x , y ) ≤ ∥ x ∥ 2 ∥ y ∥ 2 (x,y) \leq \| x\|_{2}\|
y\|_{2} ( x , y ) ≤ ∥ x ∥ 2 ∥ y ∥ 2
矩阵范数:几乎所有都使用向量范数定义∥ A ∥ p = max ∥ A x ∥ p ∥ x ∥ p = max ∥ x ∥ p = 1 ∥ A x ∥ p \| A\|_{p} = \max\frac{\| Ax\|_{p}}{\|
x\|_{p}} = \max\limits_{\| x\|_{p} = 1}\| Ax\|_{p} ∥ A ∥ p = max ∥ x ∥ p ∥ A x ∥ p = ∥ x ∥ p = 1 max ∥ A x ∥ p
1 1 1 ∥ A ∥ 1 = max 1 ≤ j ≤ n ∑ i = 1 m ∣ a i j ∣ \| A\|_{1} = \max\limits_{1 \leq j \leq n}\sum_{i =
1}^{m}|a_{ij}| ∥ A ∥ 1 = 1 ≤ j ≤ n max ∑ i = 1 m ∣ a ij ∣
2 2 2 A T A A^{T}A A T A ∥ A ∥ 2 = λ max ( A T A ) \|
A\|_{2} = \sqrt{\lambda_{\max}\left( A^{T}A \right)} ∥ A ∥ 2 = λ m a x ( A T A )
∞ \infty ∞ ∥ A ∥ ∞ = max 1 ≤ i ≤ m ∑ j = 1 n ∣ a i j ∣ \| A\|_{\infty} = \max\limits_{1 \leq i \leq
m}\sum_{j = 1}^{n}|a_{ij}| ∥ A ∥ ∞ = 1 ≤ i ≤ m max ∑ j = 1 n ∣ a ij ∣
F F F ∥ A ∥ F = ∑ ∑ ∣ a i j ∣ 2 \| A\|_{F} =
\sqrt{\sum\sum|a_{ij}|^{2}} ∥ A ∥ F = ∑∑ ∣ a ij ∣ 2
谱半径:ρ ( A ) = max ∣ λ i ∣ \rho(A) =
\max|\lambda_{i}| ρ ( A ) = max ∣ λ i ∣ ∥ λ u ∥ = ∥ A u ∥ ≤ ∥ A ∥ ∥ u ∥ \|\lambda u\|
= \| Au\| \leq \| A\|\| u\| ∥ λ u ∥ = ∥ A u ∥ ≤ ∥ A ∥∥ u ∥
方程组的性态
求解病态方程组,一般用P A x = P b PAx =
Pb P A x = P b cond ( P A ) \text{cond}(PA) cond ( P A )
高斯消元法
LU分解(直接三角分解)
存在性:A A A A A A A A A 存在且唯一 。
A = L U A = LU A = LU L L L U U U diag ( L ) \text{diag}(L) diag ( L ) diag ( R ) \text{diag}(R) diag ( R ) 1 1 1
问题变为L U x = b LUx = b LUx = b L y = b Ly = b L y = b U x = y Ux =
y Ux = y
TODO: PA=LU、追赶法、平方根法
迭代法
相容性:x ∗ = B x ∗ + f x^{\ast} = Bx^{\ast} + f x ∗ = B x ∗ + f
Jacobi迭代法:A = D − L − U A = D - L -
U A = D − L − U D x k + 1 = ( L + U ) x k + b ⟹ x k + 1 = D − 1 ( L + U ) x k + D − 1 b Dx_{k + 1} = (L + U)x_{k} + b \Longrightarrow
x_{k + 1} = D^{- 1}(L + U)x_{k} + D^{- 1}b D x k + 1 = ( L + U ) x k + b ⟹ x k + 1 = D − 1 ( L + U ) x k + D − 1 b
Gauss-Seidel迭代法:对Jacobi迭代法的改进D x k + 1 = L x k + 1 + U x k + b ⟹ x k + 1 = ( D − L ) − 1 U x k + ( D − L ) − 1 b Dx_{k + 1} = Lx_{k + 1} + Ux_{k} + b
\Longrightarrow x_{k + 1} = (D - L)^{- 1}Ux_{k} + (D - L)^{-
1}b D x k + 1 = L x k + 1 + U x k + b ⟹ x k + 1 = ( D − L ) − 1 U x k + ( D − L ) − 1 b
逐次超松弛迭代法(SOR):Gauss-Seidel迭代后加上松弛因子ω \omega ω x k + 1 = ( 1 − ω ) x k + ω x ~ k + 1 x_{k + 1} = (1 - \omega)x_{k} +
\omega{\widetilde{x}}_{k + 1} x k + 1 = ( 1 − ω ) x k + ω x k + 1 ∀ A ∈ R n × n \forall A \in R^{n \times n} ∀ A ∈ R n × n a i i ≠ 0 a_{ii} \neq 0 a ii = 0 ∀ ω \forall\omega ∀ ω ρ ( B ω ) ≥ ∣ ω − 1 ∣ \rho(B_{\omega}) \geq |\omega - 1| ρ ( B ω ) ≥ ∣ ω − 1∣ CSDN的一篇博客 。
对角占优矩阵
迭代收敛定理
收敛的一般证明方法:取e k = x k − x ∗ e_{k} = x_{k} -
x^{\ast} e k = x k − x ∗ ∥ e n ∥ → 0 \| e_{n}\|
\rightarrow 0 ∥ e n ∥ → 0
x k + 1 = B x k + f x_{k + 1} = Bx_{k} + f x k + 1 = B x k + f ⟺ ρ ( B ) < 1 \Longleftrightarrow \rho(B) <
1 ⟺ ρ ( B ) < 1 1 1 1
当A A A 0 < ω ≤ 1 0 < \omega \leq 1 0 < ω ≤ 1
SOR 收敛⟹ ∣ ω − 1 ∣ < 1 \Longrightarrow |\omega - 1| <
1 ⟹ ∣ ω − 1∣ < 1 A A A ∣ ω − 1 ∣ < 1 ⟹ |\omega - 1| < 1 \Longrightarrow ∣ ω − 1∣ < 1 ⟹
收敛率与收敛速度
要使得∥ e k ∥ ≤ σ ∥ e 0 ∥ \| e_{k}\| \leq \sigma\|
e_{0}\| ∥ e k ∥ ≤ σ ∥ e 0 ∥ ∥ B k ∥ ≤ σ \| B^{k}\| \leq
\sigma ∥ B k ∥ ≤ σ k ≥ − ln σ − ln ∥ B k ∥ 1 k k \geq \frac{-
\ln\sigma}{- \ln\| B^{k}\|^{\frac{1}{k}}} k ≥ − l n ∥ B k ∥ k 1 − l n σ
平均收敛率:R k ( B ) = − ln ∥ B k ∥ 1 k R_{k}(B) = - \ln\|
B^{k}\|^{\frac{1}{k}} R k ( B ) = − ln ∥ B k ∥ k 1
渐进收敛速度(收敛速度):R ( B ) = − ln ρ ( B ) R(B) = -
\ln\rho(B) R ( B ) = − ln ρ ( B )
使用R ( B ) R(B) R ( B ) R k ( B ) R_{k}(B) R k ( B ) k k k
TODO: 共轭梯度
非线性方程
基本概念
单根与重根:f ( x ) = ( x − x ∗ ) m g ( x ) , m ∈ N + f(x) = \left( x - x^{\ast}
\right)^{m}g(x),m \in N_{+} f ( x ) = ( x − x ∗ ) m g ( x ) , m ∈ N + x = x ∗ x =
x^{\ast} x = x ∗ f ( x ) = 0 f(x) = 0 f ( x ) = 0 m m m
二分法
若f ( x ) ∈ C [ a , b ] f(x) \in C\lbrack
a,b\rbrack f ( x ) ∈ C [ a , b ] f ( a ) f ( b ) < 0 f(a)f(b) <
0 f ( a ) f ( b ) < 0 f ( x ) = 0 f(x) = 0 f ( x ) = 0 [ a , b ] \lbrack a,b\rbrack [ a , b ] [ a , b ] \lbrack a,b\rbrack [ a , b ]
二分法即不断取中点,取新的有根区间,直至满足精度要求。
优点:好算,可靠,有大范围的收敛性。
缺点:收敛速度慢,不适用于区间内有多个根的情况。
不动点迭代法
f ( x ) = 0 ⇒ x = φ ( x ) ⇒ x k + 1 = φ ( x k ) f(x) = 0 \Rightarrow x = \varphi(x)
\Rightarrow x_{k + 1} = \varphi(x_{k}) f ( x ) = 0 ⇒ x = φ ( x ) ⇒ x k + 1 = φ ( x k ) { x k } \left\{ x_{k} \right\} { x k } f ( x ) = 0 f(x) = 0 f ( x ) = 0
若φ ( x ) \varphi(x) φ ( x ) x ∗ = φ ( x ∗ ) x^{\ast} = \varphi(x^{\ast}) x ∗ = φ ( x ∗ ) x ∗ x^{\ast} x ∗
收敛性:∀ x ∈ [ a , b ] , φ ( x ) ∈ [ a , b ] \forall x \in \lbrack
a,b\rbrack,\varphi(x) \in \lbrack a,b\rbrack ∀ x ∈ [ a , b ] , φ ( x ) ∈ [ a , b ] ∣ φ ′ ( x ) ∣ ≤ L < 1 |\varphi^{\prime}(x)| \leq L <
1 ∣ φ ′ ( x ) ∣ ≤ L < 1 [ a , b ] \lbrack
a,b\rbrack [ a , b ]
局部收敛性:φ ( x ) \varphi(x) φ ( x ) x = x ∗ x = x^{\ast} x = x ∗ ∣ φ ′ ( x ∗ ) ∣ < 1 |\varphi^{\prime}\left( x^{\ast} \right)| <
1 ∣ φ ′ ( x ∗ ) ∣ < 1
迭代收敛的阶
lim k → ∞ ∣ x k + 1 − x ∗ ∣ ∣ x k − x ∗ ∣ p = c ≠ 0 \lim\limits_{k \rightarrow
\infty}\frac{|x_{k + 1} - x^{\ast}|}{|x_{k} - x^{\ast}|^{p}} = c \neq
0 k → ∞ lim ∣ x k − x ∗ ∣ p ∣ x k + 1 − x ∗ ∣ = c = 0
p p p
p = 1 , 0 < c < 1 p = 1,0 < c <
1 p = 1 , 0 < c < 1
1 < p < 2 1 < p < 2 1 < p < 2 p = 1 , c = 0 p = 1,c = 0 p = 1 , c = 0
p = 2 p = 2 p = 2
若\varphi^{^{\prime}}(x^{\ast}) =
\varphi^{^{\prime}}^{\prime}\left( x^{\ast} \right) = \ldots = \varphi^{\left(
(p - 1) \right)\left( x^{\ast} \right)} = 0 φ ( ( p ) ) ( x ∗ ) ≠ 0 \varphi^{\left( (p) \right)\left( x^{\ast} \right)}
\neq 0 φ ( ( p ) ) ( x ∗ ) = 0 p p p lim k → ∞ ∣ x k + 1 − x ∗ ∣ ∣ x k − x ∗ ∣ p = φ ( p ) ( x ∗ ) p ! \lim\limits_{k \rightarrow \infty}\frac{|x_{k + 1}
- x^{\ast}|}{|x_{k} - x^{\ast}|^{p}} = \frac{\varphi^{(p)}\left(
x^{\ast} \right)}{p!} k → ∞ lim ∣ x k − x ∗ ∣ p ∣ x k + 1 − x ∗ ∣ = p ! φ ( p ) ( x ∗ )
特别地,∣ x ∗ − x k + 1 ∣ = ∣ φ ( x ∗ ) − φ ( x k ) ∣ = ∣ φ ′ ( ξ ) ∣ ∣ x ∗ − x k ∣ |x^{\ast} - x_{k + 1}| =
|\varphi(x^{\ast}) - \varphi(x_{k})| = |\varphi^{^{\prime}}(\xi)||x^{\ast}
- x_{k}| ∣ x ∗ − x k + 1 ∣ = ∣ φ ( x ∗ ) − φ ( x k ) ∣ = ∣ φ ′ ( ξ ) ∣∣ x ∗ − x k ∣ ∣ φ ′ ( x ∗ ) ∣ ≠ 0 |\varphi^{^{\prime}}(x^{\ast})| \neq
0 ∣ φ ′ ( x ∗ ) ∣ = 0
牛顿法
f ( x ) ≈ f ( x k ) + f ′ ( x k ) ( x − x k ) = 0 f(x) \approx f\left( x_{k} \right) +
f^{^{\prime}}(x_{k})\left( x - x_{k} \right) = 0 f ( x ) ≈ f ( x k ) + f ′ ( x k ) ( x − x k ) = 0 x k + 1 = x k − f ( x k ) f ′ ( x k ) x_{k + 1} = x_{k} - \frac{f\left( x_{k}
\right)}{f^{^{\prime}}(x_{k})} x k + 1 = x k − f ′ ( x k ) f ( x k )
收敛性:若f ( x ∗ ) = 0 , f ′ ( x ∗ ) ≠ 0 f\left( x^{\ast} \right) =
0,f^{^{\prime}}\left( x^{\ast} \right) \neq
0 f ( x ∗ ) = 0 , f ′ ( x ∗ ) = 0 2 2 2
牛顿法的重根情况
若f ( x ) = ( x − x ∗ ) m g ( x ) f(x){= \left( x - x^{\ast}
\right)}^{m}g(x) f ( x ) = ( x − x ∗ ) m g ( x ) φ ′ ( x ) = 1 − 1 m \varphi^{^{\prime}}(x)
= 1 - \frac{1}{m} φ ′ ( x ) = 1 − m 1 m > 1 m >
1 m > 1 0 < φ ′ ( x ∗ ) < 1 0 < \varphi^{^{\prime}}(x^{\ast})
< 1 0 < φ ′ ( x ∗ ) < 1
令μ = f ( x ∗ ) f ′ ( x ∗ ) \mu = \frac{f\left( x^{\ast}
\right)}{f^{^{\prime}}(x^{\ast})} μ = f ′ ( x ∗ ) f ( x ∗ ) x ∗ x^{\ast} x ∗ μ ( x ) \mu(x) μ ( x ) φ ( x ) = x − μ ( x ) μ ′ ( x ) \varphi(x) = x -
\frac{\mu(x)}{\mu^{^{\prime}}(x)} φ ( x ) = x − μ ′ ( x ) μ ( x )
割线法
用差商代替牛顿法中的导数,即x k + 1 = x k − f ( x k ) ( f ( x k ) − f ( x k − 1 ) x k − x k − 1 ) − 1 x_{k + 1} =
x_{k} - f\left( x_{k} \right)\left( \frac{f\left( x_{k} \right) -
f\left( x_{k - 1} \right)}{x_{k} - x_{k - 1}} \right)^{- 1} x k + 1 = x k − f ( x k ) ( x k − x k − 1 f ( x k ) − f ( x k − 1 ) ) − 1
收敛性:超线性收敛。
插值
拟合函数在节点处的函数值与插值函数在节点处的函数值相等(f ( x i ) = p ( x i ) f\left( x_{i} \right) = p\left( x_{i}
\right) f ( x i ) = p ( x i )
插值条件:( x i , f ( x i ) ) \left( x_{i},f\left( x_{i}
\right) \right) ( x i , f ( x i ) )
Lagrange插值
l i ( x ) = ∏ j ≠ i x − x j x i − x j , p ( x ) = ∑ i = 0 n f ( x i ) l i ( x ) l_{i}(x) = \prod_{j \neq i}\frac{x -
x_{j}}{x_{i} - x_{j}},p(x) = \sum_{i = 0}^{n}f\left( x_{i}
\right)l_{i}(x) l i ( x ) = j = i ∏ x i − x j x − x j , p ( x ) = i = 0 ∑ n f ( x i ) l i ( x )
Lagrange 插值余项:E ( x ) = f ( x ) − p ( x ) = f ( n + 1 ) ( ξ ) ( n + 1 ) ! P ( n + 1 ) ( x ) , ξ ∈ [ a , b ] E(x) = f(x) - p(x) =
\frac{f^{(n + 1)}(\xi)}{(n + 1)!}P_{(n + 1)(x)},\xi \in \lbrack
a,b\rbrack E ( x ) = f ( x ) − p ( x ) = ( n + 1 )! f ( n + 1 ) ( ξ ) P ( n + 1 ) ( x ) , ξ ∈ [ a , b ]
其中P ( n + 1 ) ( x ) = ∏ i = 0 n ( x − x i ) P_{(n + 1)(x)} = \prod_{i =
0}^{n}\left( x - x_{i} \right) P ( n + 1 ) ( x ) = ∏ i = 0 n ( x − x i )
Lagrange 插值余项E ( x ) E(x) E ( x )
由定义得E ( x i ) = 0 , i = 0 , 1 , … , n E\left( x_{i} \right) = 0,i =
0,1,\ldots,n E ( x i ) = 0 , i = 0 , 1 , … , n E ( x ) = Q ( x ) P ( n + 1 ) ( x ) E(x) = Q(x)P_{(n +
1)(x)} E ( x ) = Q ( x ) P ( n + 1 ) ( x ) Q ( x ) Q(x) Q ( x ) φ ( x ) = f ( x ) − L n ( x ) − Q ( x ∗ ) P ( n + 1 ) ( x ) \varphi(x) = f(x) - L_{n}(x) - Q\left( x^{\ast}
\right)P_{(n + 1)(x)} φ ( x ) = f ( x ) − L n ( x ) − Q ( x ∗ ) P ( n + 1 ) ( x ) x ∗ x^{\ast} x ∗ x 0 , x 1 , … , x n x_{0},x_{1},\ldots,x_{n} x 0 , x 1 , … , x n φ ( x ) \varphi(x) φ ( x ) n + 2 n +
2 n + 2 φ ( n + 1 ) \varphi^{(n +
1)} φ ( n + 1 ) n + 1 n + 1 n + 1 φ ( n + 1 ) \varphi^{(n + 1)} φ ( n + 1 ) t = ξ t = \xi t = ξ φ ( n + 1 ) ( ξ ) = f ( n + 1 ) ( ξ ) − 0 − Q ( x ∗ ) ( n + 1 ) ! = 0 ⇒ Q ( x ∗ ) = f ( n + 1 ) ( ξ ) ( n + 1 ) ! \varphi^{(n + 1)}(\xi) = f^{(n + 1)}(\xi) - 0 -
Q\left( x^{\ast} \right)(n + 1)! = 0 \Rightarrow Q\left( x^{\ast}
\right) = \frac{f^{(n + 1)}(\xi)}{(n + 1)!} φ ( n + 1 ) ( ξ ) = f ( n + 1 ) ( ξ ) − 0 − Q ( x ∗ ) ( n + 1 )! = 0 ⇒ Q ( x ∗ ) = ( n + 1 )! f ( n + 1 ) ( ξ )
缺点:加入节点需要重新计算所有的插值多项式。
Newton插值
差商
k k k
f [ x 0 , x 1 , … , x k ] = f [ x 1 , x 2 , … , x k ] − f [ x 0 , x 1 , … , x k − 1 ] x k − x 0 f\left\lbrack x_{0},x_{1},\ldots,x_{k}
\right\rbrack = \frac{f\left\lbrack x_{1},x_{2},\ldots,x_{k}
\right\rbrack - f\left\lbrack x_{0},x_{1},\ldots,x_{k - 1}
\right\rbrack}{x_{k} - x_{0}} f [ x 0 , x 1 , … , x k ] = x k − x 0 f [ x 1 , x 2 , … , x k ] − f [ x 0 , x 1 , … , x k − 1 ]
差商具有对称性(交换节点不影响差商的值)。
差商表
利用f [ x 0 , x 1 , … , x k − 1 ] f\left\lbrack x_{0},x_{1},\ldots,x_{k -
1} \right\rbrack f [ x 0 , x 1 , … , x k − 1 ] f [ x 1 , x 2 , … , x k ] f\left\lbrack
x_{1},x_{2},\ldots,x_{k} \right\rbrack f [ x 1 , x 2 , … , x k ] f [ x 0 , x 1 , … , x k ] f\left\lbrack x_{0},x_{1},\ldots,x_{k}
\right\rbrack f [ x 0 , x 1 , … , x k ]
Newton插值多项式
f ( x ) = f [ x 0 ] + f [ x 0 , x 1 ] ( x − x 0 ) + f [ x 0 , x 1 , x 2 ] ( x − x 0 ) ( x − x 1 ) + … + f [ x 0 , x 1 , … , x n ] ( x − x 0 ) ( x − x 1 ) … ( x − x n − 1 ) + f [ x , x 0 , x 1 , … , x n ] ( x − x 0 ) ( x − x 1 ) … ( x − x n ) = N n ( x ) + f [ x , x 0 , x 1 , … , x n ] P n + 1 ( x ) \begin{aligned}
f(x) & = f\left\lbrack x_{0} \right\rbrack & & +
f\left\lbrack x_{0},x_{1} \right\rbrack\left( x - x_{0} \right) +
f\left\lbrack x_{0},x_{1},x_{2} \right\rbrack\left( x - x_{0}
\right)\left( x - x_{1} \right) + \ldots \\
& & & + f\left\lbrack x_{0},x_{1},\ldots,x_{n}
\right\rbrack\left( x - x_{0} \right)\left( x - x_{1}
\right)\ldots\left( x - x_{n - 1} \right) \\
& & & + f\left\lbrack x,x_{0},x_{1},\ldots,x_{n}
\right\rbrack\left( x - x_{0} \right)\left( x - x_{1}
\right)\ldots\left( x - x_{n} \right) \\
& = N_{n}(x) & & + f\left\lbrack x,x_{0},x_{1},\ldots,x_{n}
\right\rbrack P_{n + 1}(x)
\end{aligned} f ( x ) = f [ x 0 ] = N n ( x ) + f [ x 0 , x 1 ] ( x − x 0 ) + f [ x 0 , x 1 , x 2 ] ( x − x 0 ) ( x − x 1 ) + … + f [ x 0 , x 1 , … , x n ] ( x − x 0 ) ( x − x 1 ) … ( x − x n − 1 ) + f [ x , x 0 , x 1 , … , x n ] ( x − x 0 ) ( x − x 1 ) … ( x − x n ) + f [ x , x 0 , x 1 , … , x n ] P n + 1 ( x )
插值余项:E ( x ) = f ( x ) − N n ( x ) = f [ x , x 0 , x 1 , … , x n ] P n + 1 ( x ) E(x) = f(x) - N_{n}(x) =
f\left\lbrack x,x_{0},x_{1},\ldots,x_{n} \right\rbrack P_{n +
1}(x) E ( x ) = f ( x ) − N n ( x ) = f [ x , x 0 , x 1 , … , x n ] P n + 1 ( x )
⇒ f [ x , x 0 , x 1 , … , x n ] = f n + 1 ( ξ ) ( n + 1 ) ! \Rightarrow f\left\lbrack
x,x_{0},x_{1},\ldots,x_{n} \right\rbrack = \frac{f^{n + 1}(\xi)}{(n +
1)!} ⇒ f [ x , x 0 , x 1 , … , x n ] = ( n + 1 )! f n + 1 ( ξ )
Hermite插值
不仅给出函数值,还给出导数值。给出n + 1 n +
1 n + 1 r + 1 r + 1 r + 1 n + r + 2 n + r + 2 n + r + 2
构造基函数的步骤:
明确基函数的次数
如果α ( x k ) = α ′ ( x k ) = … = α r − 1 ( x k ) = 0 \alpha(x_{k}) =
\alpha^{^{\prime}}\left( x_{k} \right) = \ldots = \alpha^{r - 1}\left(
x_{k} \right) = 0 α ( x k ) = α ′ ( x k ) = … = α r − 1 ( x k ) = 0 x k x_{k} x k r r r α ( x k ) = ( l k ( x ) ) r g ( x ) \alpha(x_{k}) = \left( l_{k}(x)
\right)^{r}g(x) α ( x k ) = ( l k ( x ) ) r g ( x )
g ( x ) g(x) g ( x ) a x + b ax + b a x + b
将其他条件代入,解出g ( x ) g(x) g ( x )
分段插值
将插值区间分为若干段,每段使用一个插值多项式。
线性插值:p ( x ) = f ( x i ) + f ( x i + 1 ) − f ( x i ) x i + 1 − x i ( x − x i ) p(x) = f\left( x_{i} \right)
+ \frac{f\left( x_{i + 1} \right) - f\left( x_{i} \right)}{x_{i + 1} -
x_{i}}\left( x - x_{i} \right) p ( x ) = f ( x i ) + x i + 1 − x i f ( x i + 1 ) − f ( x i ) ( x − x i )
三次 Hermite
插值:有每个点的函数值和导数值,每个区间使用一个三次多项式。
Runge 现象
TODO
拟合
函数的内积、范数与正交性
设f ( x ) , g ( x ) f(x),g(x) f ( x ) , g ( x ) [ a , b ] \lbrack a,b\rbrack [ a , b ]
( f , g ) = ∫ a b f ( x ) g ( x ) d x (f,g) = \int_{a}^{b}f(x)g(x)dx ( f , g ) = ∫ a b f ( x ) g ( x ) d x
定义范数:
∥ f ∥ 1 = ∫ a b ∣ f ( x ) ∣ d x \| f\|_{1} =
\int_{a}^{b}|f(x)|dx ∥ f ∥ 1 = ∫ a b ∣ f ( x ) ∣ d x
∥ f ∥ 2 = ( f , f ) \| f\|_{2} =
\sqrt{(f,f)} ∥ f ∥ 2 = ( f , f )
∥ f ∥ ∞ = max a ≤ x ≤ b ∣ f ( x ) ∣ \| f\|_{\infty} = \max\limits_{a \leq x
\leq b}|f(x)| ∥ f ∥ ∞ = a ≤ x ≤ b max ∣ f ( x ) ∣
若函数系列{ φ i } \left\{ \varphi_{i}
\right\} { φ i } ( φ i , φ j ) = 0 , i ≠ j \left(
\varphi_{i},\varphi_{j} \right) = 0,i \neq
j ( φ i , φ j ) = 0 , i = j
Gram 矩阵与正则方程
设Φ = { φ 1 , φ 2 , … , φ n } \Phi = \left\{
\varphi_{1},\varphi_{2},\ldots,\varphi_{n} \right\} Φ = { φ 1 , φ 2 , … , φ n } Φ \Phi Φ G G G G i , j = ( φ i , φ j ) G_{i,j} =
\left( \varphi_{i},\varphi_{j} \right) G i , j = ( φ i , φ j )
函数系线性无关的充要条件是 det G ≠ 0 \det G \neq
0 det G = 0
正则方程为 G a = b Ga = b G a = b a = ( a 1 , a 2 , … , a n ) T a = \left( a_{1},a_{2},\ldots,a_{n}
\right)^{T} a = ( a 1 , a 2 , … , a n ) T b = ( ( f , φ 1 ) , ( f , φ 2 ) , … , ( f , φ n ) ) T b = \left( \left(
f,\varphi_{1} \right),\left( f,\varphi_{2} \right),\ldots,\left(
f,\varphi_{n} \right) \right)^{T} b = ( ( f , φ 1 ) , ( f , φ 2 ) , … , ( f , φ n ) ) T
正则方程也可以写为 A T A a = A T f A^{T}Aa =
A^{T}f A T A a = A T f A = ( φ 1 , φ 2 , … , φ n ) A = \left(
\varphi_{1},\varphi_{2},\ldots,\varphi_{n} \right) A = ( φ 1 , φ 2 , … , φ n )
函数逼近
设X X X Φ \Phi Φ X X X f ∈ X f
\in X f ∈ X φ ∈ Φ \varphi \in
\Phi φ ∈ Φ ∥ f − φ ∥ \| f -
\varphi\| ∥ f − φ ∥ φ \varphi φ f f f Φ \Phi Φ φ \varphi φ f f f Φ \Phi Φ φ \varphi φ f f f Φ \Phi Φ
最佳二次逼近
唯一性:f ( x ) f(x) f ( x ) Φ \Phi Φ φ ( x ) \varphi(x) φ ( x )
设最佳逼近为 φ ( x ) = a 0 φ 0 ( x ) + ⋯ + a m φ m ( x ) \varphi(x) =
a_{0}\varphi_{0}(x) + \cdots + a_{m}\varphi_{m}(x) φ ( x ) = a 0 φ 0 ( x ) + ⋯ + a m φ m ( x ) ∥ E ( x ) ∥ 2 2 = ( f − y ∗ , f − y ∗ ) = ∥ f ∥ 2 2 − ∑ j = 0 m a j ∗ ( f , φ j ) \| E(x)\|_{2}^{2} = \left( f - y^{\ast},f -
y^{\ast} \right) = \| f\|_{2}^{2} - \sum_{j = 0}^{m}a_{j}^{\ast}\left(
f,\varphi_{j} \right) ∥ E ( x ) ∥ 2 2 = ( f − y ∗ , f − y ∗ ) = ∥ f ∥ 2 2 − j = 0 ∑ m a j ∗ ( f , φ j )
若记正则方程为 G a = b Ga = b G a = b ∥ E ( x ) ∥ 2 2 = ∥ f ∥ 2 2 − b T a \| E(x)\|_{2}^{2} = \| f\|_{2}^{2} -
b^{T}a ∥ E ( x ) ∥ 2 2 = ∥ f ∥ 2 2 − b T a
多项式作二次逼近
只需讨论[ 0 , 1 ] \lbrack
0,1\rbrack [ 0 , 1 ] Φ = { 1 , x , x 2 , … , x n } \Phi =
\left\{ 1,x,x^{2},\ldots,x^{n} \right\} Φ = { 1 , x , x 2 , … , x n } G G G n + 1 n + 1 n + 1 H i j = 1 i + j − 1 H_{ij} = \frac{1}{i + j -
1} H ij = i + j − 1 1 ( ( f , 1 ) , ( f , x ) , … , ( f , x n ) ) T \left(
(f,1),(f,x),\ldots,\left( f,x^{n} \right) \right)^{T} ( ( f , 1 ) , ( f , x ) , … , ( f , x n ) ) T a a a
Hilbert 矩阵是一个病态矩阵,其条件数随着阶数的增加而迅速增大。
正交多项式作二次逼近
若取正交多项式作为基函数,则 G G G a j = ( f , φ j ) ( φ j , φ j ) , y ∗ ( x ) = ∑ j = 0 n a j φ j ( x ) a_{j} = \frac{\left(
f,\varphi_{j} \right)}{\left( \varphi_{j},\varphi_{j} \right)},y^{\ast
(x)} = \sum_{j = 0}^{n}a_{j}\varphi_{j}(x) a j = ( φ j , φ j ) ( f , φ j ) , y ∗ ( x ) = j = 0 ∑ n a j φ j ( x )
Legendre 多项式
P n ( x ) = 1 2 n n ! d n d x n ( x 2 − 1 ) n P_{n}(x) =
\frac{1}{2^{n}n!}\frac{d^{n}}{dx^{n}}\left( x^{2} - 1
\right)^{n} P n ( x ) = 2 n n ! 1 d x n d n ( x 2 − 1 ) n
Legendre 的正交区间为 [ − 1 , 1 ] \lbrack -
1,1\rbrack [ − 1 , 1 ]
a j ∗ = 2 j + 1 2 ∫ − 1 1 f ( x ) P j ( x ) d x , E ( x ) = ∥ f ∥ 2 2 − ∑ j = 0 n 2 2 j + 1 ( a j ∗ ) 2 a_{j}^{\ast} = \frac{2j + 1}{2}\int_{-
1}^{1}f(x)P_{j}(x)dx,E(x) = \| f\|_{2}^{2} - \sum_{j = 0}^{n}\frac{2}{2j
+ 1}\left( a_{j}^{\ast} \right)^{2} a j ∗ = 2 2 j + 1 ∫ − 1 1 f ( x ) P j ( x ) d x , E ( x ) = ∥ f ∥ 2 2 − j = 0 ∑ n 2 j + 1 2 ( a j ∗ ) 2
一个递推公式:( n + 1 ) P n + 1 = ( 2 n + 1 ) x P n − n P n − 1 (n + 1)P_{n + 1} = (2n +
1)xP_{n} - nP_{n - 1} ( n + 1 ) P n + 1 = ( 2 n + 1 ) x P n − n P n − 1
Chebyshev 多项式
T n ( x ) = cos ( n arccos x ) T_{n}(x) = \cos(n\arccos x) T n ( x ) = cos ( n arccos x )
TODO
最小二乘数据拟合
设数据为 { ( x i , f i ) } \left\{ \left( x_{i},f_{i} \right)
\right\} { ( x i , f i ) } y ( x ) = argmin φ ∈ Φ ∑ i = 1 n ( f i − φ ( x i ) ) 2 y(x) = \text{
argmin}_{\varphi \in \Phi}\sum_{i = 1}^{n}\left( f_{i} - \varphi(x_{i})
\right)^{2} y ( x ) = argmin φ ∈ Φ ∑ i = 1 n ( f i − φ ( x i ) ) 2
最小二乘存在且唯一。
多项式最小二乘拟合
设 Φ = { 1 , x , x 2 , … , x n } \Phi = \left\{ 1,x,x^{2},\ldots,x^{n}
\right\} Φ = { 1 , x , x 2 , … , x n } G G G n + 1 n + 1 n + 1 G i , j = ∑ k = 0 n x k i + j , b j = ∑ i = 1 n f i x i j G_{i,j} = \sum_{k = 0}^{n}x_{k}^{i + j},b_{j} =
\sum_{i = 1}^{n}f_{i}x_{i}^{j} G i , j = k = 0 ∑ n x k i + j , b j = i = 1 ∑ n f i x i j
可以列表计算:i , x i , x i 2 , … , x i n , f i , f i x i , … , f i x i n i,x_{i},x_{i}^{2},\ldots,x_{i}^{n},f_{i},f_{i}x_{i},\ldots,f_{i}x_{i}^{n} i , x i , x i 2 , … , x i n , f i , f i x i , … , f i x i n
如果函数合适,可以做变换使得问题变为线性拟合问题。
数值积分
∫ a b f ( x ) d x = ∑ j = 0 n A j f ( x j ) + E ( f ) \int_{a}^{b}f(x)dx = \sum_{j =
0}^{n}A_{j}f\left( x_{j} \right) + E(f) ∫ a b f ( x ) d x = ∑ j = 0 n A j f ( x j ) + E ( f ) A j A_{j} A j x j x_{j} x j f f f E ( f ) E(f) E ( f )
代数精度
若求积公式对所有次数不超过n n n n + 1 n + 1 n + 1 n n n
定理:给定n + 1 n + 1 n + 1 x 0 , x 1 , … , x n x_{0},x_{1},\ldots,x_{n} x 0 , x 1 , … , x n A 0 , A 1 , … , A n A_{0},A_{1},\ldots,A_{n} A 0 , A 1 , … , A n n n n
插值型求积公式
由 Lagrange 插值多项式 f ( x ) = ∑ i = 0 n f ( x i ) l i ( x ) + f n + 1 ( ξ ) ( n + 1 ) ! P n + 1 ( x ) f(x) = \sum_{i =
0}^{n}f\left( x_{i} \right)l_{i}(x) + \frac{f^{n + 1}(\xi)}{(n +
1)!}P_{n + 1}(x) f ( x ) = ∑ i = 0 n f ( x i ) l i ( x ) + ( n + 1 )! f n + 1 ( ξ ) P n + 1 ( x ) A j = ∫ a b l j ( x ) d x A_{j} = \int_{a}^{b}l_{j}(x)dx A j = ∫ a b l j ( x ) d x
Newton-Cotes 求积公式
将区间[ a , b ] \lbrack a,b\rbrack [ a , b ] n n n h = ( b − a ) n h\frac{= (b - a)}{n} h n = ( b − a ) x i = a + i h x_{i} = a + ih x i = a + ih
令x = a + t h x = a + th x = a + t h l j ( x ) = ∏ k ≠ j x − x k x j − x k = ∏ k ≠ j t − k j − k l_{j}(x) = \prod_{k \neq j}\frac{x - x_{k}}{x_{j} -
x_{k}} = \prod_{k \neq j}\frac{t - k}{j - k} l j ( x ) = k = j ∏ x j − x k x − x k = k = j ∏ j − k t − k
代入得到A j = ∫ a b l j ( x ) d x = ( − 1 ) n − j h j ! ( n − j ) ! ∫ 0 n ∏ k ≠ j ( t − k ) d t A_{j} = \int_{a}^{b}l_{j}(x)dx =
\frac{( - 1)^{n - j}h}{j!(n - j)!}\int_{0}^{n}\prod_{k \neq j}(t -
k)dt A j = ∫ a b l j ( x ) d x = j ! ( n − j )! ( − 1 ) n − j h ∫ 0 n k = j ∏ ( t − k ) d t
令C j = A j b − a = ( − 1 ) n − j n ⋅ j ! ( n − j ) ! ∫ 0 n ∏ k ≠ j ( t − k ) d t C_{j} = \frac{A_{j}}{b - a} = \frac{( -
1)^{n - j}}{n \cdot j!(n - j)!}\int_{0}^{n}\prod_{k \neq j}(t -
k)dt C j = b − a A j = n ⋅ j ! ( n − j )! ( − 1 ) n − j ∫ 0 n ∏ k = j ( t − k ) d t ∫ a b f ( x ) d x = ( b − a ) ∑ j = 0 n C j f ( x j ) + E \int_{a}^{b}f(x)dx =
(b - a)\sum_{j = 0}^{n}C_{j}f\left( x_{j} \right) + E ∫ a b f ( x ) d x = ( b − a ) j = 0 ∑ n C j f ( x j ) + E
取f ( x ) ≡ 1 f(x) \equiv 1 f ( x ) ≡ 1 ∑ C j = 1 \sum C_{j} = 1 ∑ C j = 1
梯形公式:n = 1 , C 0 = C 1 = 1 2 , E = − h 3 12 f ′ ′ ( ξ ) n = 1,C_{0} = C_{1} =
\frac{1}{2},E = - \frac{h^{3}}{12}f^{^{\prime\prime}}(\xi) n = 1 , C 0 = C 1 = 2 1 , E = − 12 h 3 f ′′ ( ξ )
Simpson 公式:n = 2 , C 0 = C 2 = 1 6 , C 1 = 4 6 , E = − h 5 90 f ( 4 ) ( ξ ) n = 2,C_{0} = C_{2} =
\frac{1}{6},C_{1} = \frac{4}{6},E = -
\frac{h^{5}}{90}f^{(4)}(\xi) n = 2 , C 0 = C 2 = 6 1 , C 1 = 6 4 , E = − 90 h 5 f ( 4 ) ( ξ )
… \ldots …
当n n n n + 1 n + 1 n + 1 n + 1 n + 1 n + 1
稳定性:TODO
复化求积公式
将区间[ a , b ] \lbrack a,b\rbrack [ a , b ] n n n n n n 2 k 2^{k} 2 k
复化梯形公式
令T n T_{n} T n n n n T n = h 2 ( f ( a ) + 2 ∑ i = 1 n − 1 f ( x i ) + f ( b ) ) T_{n} = \frac{h}{2}\left( f(a) + 2\sum_{i = 1}^{n -
1}f\left( x_{i} \right) + f(b)
\right) T n = 2 h ( f ( a ) + 2 ∑ i = 1 n − 1 f ( x i ) + f ( b ) ) U n = h ∑ i = 0 n − 1 f ( x i + 1 2 ) U_{n} = h\sum_{i = 0}^{n - 1}f\left( x_{i +
\frac{1}{2}} \right) U n = h ∑ i = 0 n − 1 f ( x i + 2 1 ) n n n T 2 n = 1 2 ( T n + U n ) T_{2n} = \frac{1}{2}\left( T_{n} + U_{n}
\right) T 2 n = 2 1 ( T n + U n )
余项:TODO
复化 Simpson 公式
S n = h 6 ∑ ( f ( x i ) + 4 f ( x i + 1 2 ) + f ( x i + 1 ) ) = 1 3 T n + 2 3 U n = 4 T 2 n − T n 4 − 1 S_{n} = \frac{h}{6}\sum(f\left( x_{i}
\right) + 4f\left( x_{i + \frac{1}{2}} \right) + f\left( x_{i + 1}
\right)) = \frac{1}{3}T_{n} + \frac{2}{3}U_{n} = \frac{4T_{2n} -
T_{n}}{4 - 1} S n = 6 h ∑ ( f ( x i ) + 4 f ( x i + 2 1 ) + f ( x i + 1 ) ) = 3 1 T n + 3 2 U n = 4 − 1 4 T 2 n − T n
余项:TODO
变步长
给定ε \varepsilon ε ∣ S 2 k − S 2 k − 1 ∣ < ε |S_{2^{k}} - S_{2^{k - 1}}| <
\varepsilon ∣ S 2 k − S 2 k − 1 ∣ < ε
Romberg 求积
由泰勒展开可以得到I = ∫ a b f ( x ) d x = h 2 ( f ( a ) + 2 ∑ i = 1 n − 1 f ( x i ) + f ( b ) ) + ∑ j = 1 ∞ α j h 2 j ≜ T ( h ) − ∑ j = 1 ∞ α j h 2 j I = \int_{a}^{b}f(x)dx =
\frac{h}{2}\left( f(a) + 2\sum_{i = 1}^{n - 1}f\left( x_{i} \right) +
f(b) \right) + \sum_{j = 1}^{\infty}\alpha_{j}h^{2j} \triangleq T(h) -
\sum_{j = 1}^{\infty}\alpha_{j}h^{2j} I = ∫ a b f ( x ) d x = 2 h ( f ( a ) + 2 i = 1 ∑ n − 1 f ( x i ) + f ( b ) ) + j = 1 ∑ ∞ α j h 2 j ≜ T ( h ) − j = 1 ∑ ∞ α j h 2 j T ( h ) T(h) T ( h ) { T 0 ( h ) ≜ T ( h ) = I + α 1 h 2 + α 2 h 4 + … T ( h 2 ) = I + α 1 h 2 4 + α 2 h 4 16 + … ⇒ T 1 ( h ) ≜ 4 T ( h 2 ) − T ( h ) 4 − 1 = I + β 1 h 4 + … \begin{cases}
T_{0}(h) \triangleq T(h) = I + \alpha_{1}h^{2} + \alpha_{2}h^{4} +
\ldots \\
T\left( \frac{h}{2} \right) = I + \alpha_{1}\frac{h^{2}}{4} +
\alpha_{2}\frac{h^{4}}{16} + \ldots
\end{cases} \Rightarrow T_{1}(h) \triangleq \frac{4T\left( \frac{h}{2}
\right) - T(h)}{4 - 1} = I + \beta_{1}h^{4} + \ldots { T 0 ( h ) ≜ T ( h ) = I + α 1 h 2 + α 2 h 4 + … T ( 2 h ) = I + α 1 4 h 2 + α 2 16 h 4 + … ⇒ T 1 ( h ) ≜ 4 − 1 4 T ( 2 h ) − T ( h ) = I + β 1 h 4 + … T m ( h ) T_{m}(h) T m ( h ) h 2 ( m + 1 ) h^{2(m + 1)} h 2 ( m + 1 ) T 1 ( h ) T_{1}(h) T 1 ( h ) T 2 ( h ) T_{2}(h) T 2 ( h )
为了方便计算,将区间[ a , b ] \lbrack
a,b\rbrack [ a , b ] 2 k 2^{k} 2 k T 0 , k T_{0,k} T 0 , k T 0 , 0 = b − a 2 ( f ( a ) + f ( b ) ) , U 0 , 0 = ( b − a ) f ( a + b 2 ) U 0 , k − 1 = b − a 2 k − 1 ∑ i = 1 2 k − 1 f ( a + ( 2 i − 1 ) b − a 2 k ) , T 0 , k = 1 2 ( T 0 , k − 1 + U 0 , k − 1 ) T m , k = 4 m T m − 1 , k + 1 − T m − 1 , k 4 m − 1 \begin{aligned}
T_{0,0} & = \frac{b - a}{2}\left( f(a) + f(b) \right),U_{0,0} = (b -
a)f\left( \frac{a + b}{2} \right) \\
U_{0,k - 1} & = \frac{b - a}{2^{k - 1}}\sum_{i = 1}^{2^{k -
1}}f\left( a + (2i - 1)\frac{b - a}{2^{k}} \right),T_{0,k} =
\frac{1}{2}\left( T_{0,k - 1} + U_{0,k - 1} \right) \\
T_{m,k} & = \frac{4^{m}T_{m - 1,k + 1} - T_{m - 1,k}}{4^{m} - 1}
\end{aligned} T 0 , 0 U 0 , k − 1 T m , k = 2 b − a ( f ( a ) + f ( b ) ) , U 0 , 0 = ( b − a ) f ( 2 a + b ) = 2 k − 1 b − a i = 1 ∑ 2 k − 1 f ( a + ( 2 i − 1 ) 2 k b − a ) , T 0 , k = 2 1 ( T 0 , k − 1 + U 0 , k − 1 ) = 4 m − 1 4 m T m − 1 , k + 1 − T m − 1 , k
可以列表计算:
m = 0 m = 0 m = 0
m = 1 m = 1 m = 1
m = 2 m = 2 m = 2
m = 3 m = 3 m = 3
i = 0 i = 0 i = 0
T 0 , 0 T_{0,0} T 0 , 0
i = 1 i = 1 i = 1
T 0 , 1 T_{0,1} T 0 , 1
T 1 , 0 T_{1,0} T 1 , 0
i = 2 i = 2 i = 2
T 0 , 2 T_{0,2} T 0 , 2
T 1 , 1 T_{1,1} T 1 , 1
T 2 , 0 T_{2,0} T 2 , 0
i = 3 i = 3 i = 3
T 0 , 3 T_{0,3} T 0 , 3
T 1 , 2 T_{1,2} T 1 , 2
T 2 , 1 T_{2,1} T 2 , 1
T 3 , 0 T_{3,0} T 3 , 0
Gauss 求积
Newton-Cotes 求积公式的节点是等距的,而 Gauss
求积公式通过选取合适的节点,使得求积公式具有更高的代数精度。对于有n + 1 n + 1 n + 1 2 n + 1 2n +
1 2 n + 1 f ( x ) = 1 , x , … , x 2 n + 1 f(x) = 1,x,\ldots,x^{2n + 1} f ( x ) = 1 , x , … , x 2 n + 1 2 n + 2 2n + 2 2 n + 2 2 n + 2 2n +
2 2 n + 2 A 0 ∼ A n , x 0 ∼ x n A_{0}\sim A_{n},x_{0}\sim
x_{n} A 0 ∼ A n , x 0 ∼ x n
原理:对 Hermite 插值多项式左右两边同时积分,则有∫ a b f ( x ) d x = ∑ i = 0 n H i f ( x i ) + ∑ i = 0 n H ‾ i ( x ) f ′ ( x i ) + f ( 2 n + 2 ) ( ξ ) ( 2 n + 2 ) ! ∫ a b P n + 1 2 ( x ) d x \int_{a}^{b}f(x)dx = \sum_{i = 0}^{n}H_{i}f\left(
x_{i} \right) + \sum_{i = 0}^{n}{\overline{H}}_{i}(x)f^{^{\prime}}\left(
x_{i} \right) + \frac{f^{(2n + 2)}(\xi)}{(2n + 2)!}\int_{a}^{b}P_{n +
1}^{2}(x)dx ∫ a b f ( x ) d x = i = 0 ∑ n H i f ( x i ) + i = 0 ∑ n H i ( x ) f ′ ( x i ) + ( 2 n + 2 )! f ( 2 n + 2 ) ( ξ ) ∫ a b P n + 1 2 ( x ) d x H H H H ‾ \overline{H} H h h h h ‾ \overline{h} h H ‾ i ( x ) = 0 {\overline{H}}_{i}(x) = 0 H i ( x ) = 0 ∫ a b f ( x ) d x = ∑ i = 0 n H i f ( x i ) + E ( f ) \int_{a}^{b}f(x)dx = \sum_{i = 0}^{n}H_{i}f\left(
x_{i} \right) + E(f) ∫ a b f ( x ) d x = ∑ i = 0 n H i f ( x i ) + E ( f )
定理:x 0 , … , x n x_{0},\ldots,x_{n} x 0 , … , x n ⇔ ω ( x ) = ∏ k = 0 n ( x − x k ) \Leftrightarrow \omega(x) = \prod_{k =
0}^{n}\left( x - x_{k} \right) ⇔ ω ( x ) = ∏ k = 0 n ( x − x k ) n n n
通过这条定理,取一个正交多项式系{ φ 0 , φ 1 , … , φ n , φ n + 1 } \left\{
\varphi_{0},\varphi_{1},\ldots,\varphi_{n},\varphi_{n + 1}
\right\} { φ 0 , φ 1 , … , φ n , φ n + 1 } φ n + 1 \varphi_{n +
1} φ n + 1
Gauss-Legendre 求积
取区间[ − 1 , 1 ] \lbrack - 1,1\rbrack [ − 1 , 1 ] φ n \varphi_{n} φ n P n ( x ) = 1 2 n n ! d n d x n ( x 2 − 1 ) n P_{n}(x) =
\frac{1}{2^{n}n!}\frac{d^{n}}{dx^{n}}\left( x^{2} - 1
\right)^{n} P n ( x ) = 2 n n ! 1 d x n d n ( x 2 − 1 ) n x i x_{i} x i A i = 2 ( 1 − x i 2 ) ( φ n + 1 ′ ( x i ) ) 2 A_{i} = \frac{2}{\left( 1 -
x_{i}^{2} \right)\left( \varphi_{n + 1}^{^{\prime}}\left( x_{i} \right)
\right)^{2}} A i = ( 1 − x i 2 ) ( φ n + 1 ′ ( x i ) ) 2 2 φ n + 1 \varphi_{n +
1} φ n + 1
其他的 Gauss 求积
Chebyshev 多项式:权函数为1 1 − x 2 \frac{1}{\sqrt{1
- x^{2}}} 1 − x 2 1 [ − 1 , 1 ] \lbrack -
1,1\rbrack [ − 1 , 1 ] T n + 1 ( x ) T_{n +
1}(x) T n + 1 ( x ) x j = cos ( 2 j + 1 2 n + 2 π ) x_{j} = \cos(\frac{2j +
1}{2n + 2}\pi) x j = cos ( 2 n + 2 2 j + 1 π ) A j = π n + 1 A_{j} =
\frac{\pi}{n + 1} A j = n + 1 π
Laguerre 多项式:权函数为e − x e^{-
x} e − x [ 0 , + ∞ ) \lbrack 0, +
\infty) [ 0 , + ∞ )
Hermite 多项式:权函数为e − x 2 e^{-
x^{2}} e − x 2 ( − ∞ , + ∞ ) ( - \infty, +
\infty) ( − ∞ , + ∞ )
对于有权函数的 Gauss 求积,所求积分的形式为∫ a b ρ ( x ) f ( x ) d x \int_{a}^{b}\rho(x)f(x)dx ∫ a b ρ ( x ) f ( x ) d x ρ ( x ) \rho(x) ρ ( x ) ∑ j = 0 n A j f ( x j ) \sum_{j = 0}^{n}A_{j}f\left( x_{j}
\right) ∑ j = 0 n A j f ( x j ) ∑ j = 0 n A j ρ ( x j ) f ( x j ) \sum_{j =
0}^{n}A_{j}\rho(x_{j})f\left( x_{j} \right) ∑ j = 0 n A j ρ ( x j ) f ( x j )
数值微分
Lagrange 插值多项式求数值微分
对 Lagrange 插值多项式求导即可得到数值微分的结果。 f ( k ) ( x ) = ∑ i = 0 n f ( x i ) l i ( k ) ( x ) + ( E ( x ) ) ( k ) f^{(k)}(x) = \sum_{i = 0}^{n}f\left( x_{i}
\right)l_{i}^{(k)}(x) + \left( E(x) \right)^{(k)} f ( k ) ( x ) = i = 0 ∑ n f ( x i ) l i ( k ) ( x ) + ( E ( x ) ) ( k )
差商代替微商求函数的数值微分
向前差商:f^{^{\prime}}(x) = \frac{f(x + h) -
f(x)}{h} - \frac{h}{2}f^{^{\prime}}^{\prime}(\xi)
向后差商:f^{^{\prime}}(x) = \frac{f(x) - f(x
- h)}{h} + \frac{h}{2}f^{^{\prime}}^{\prime}(\xi)
中心差商:f^{^{\prime}}(x) = \frac{f(x + h) -
f(x - h)}{2}h - \frac{h^{2}}{6}f^{^{\prime}}^{\prime\prime}(\xi)
二阶中心差商:f^{^{\prime}}^{\prime}(x) =
\frac{f(x + h) - 2f(x) + f(x - h)}{h^{2}} -
\frac{h^{2}}{12}f^{(4)}(\xi)
Richardson 外推法求数值微分
\begin{array}{r}
f(x + h) = f(x) + hf^{^{\prime}}(x) + \frac{h^{2}}{2}f^{^{\prime}}^{\prime}(x) +
\frac{h^{3}}{6}f^{^{\prime}}^{\prime\prime}(x) + \ldots \\
f(x - h) = f(x) - hf^{^{\prime}}(x) + \frac{h^{2}}{2}f^{^{\prime}}^{\prime}(x) -
\frac{h^{3}}{6}f^{^{\prime}}^{\prime\prime}(x) + \ldots \\
\Rightarrow f^{^{\prime}}(x) - \frac{f(x + h) - f(x - h)}{2h} = - \sum_{k =
1}^{\infty}\left( \frac{h^{2k}}{(2k + 1)!}f^{(2k + 1)}(x) \right)
\end{array}
由 Richardson 外推法可构造递推公式:(其中T ( h ) T(h) T ( h ) h h h { T 0 ( h ) = T ( h ) = f ( x + h 2 ) − f ( x − h 2 ) h T m ( h ) = 4 m T m − 1 ( h 2 ) − T m − 1 ( h ) 4 m − 1 \begin{cases}
T_{0}(h) & = T(h) = \frac{f\left( x + \frac{h}{2} \right) - f\left(
x - \frac{h}{2} \right)}{h} \\
T_{m}(h) & = \frac{4^{m}T_{m - 1}\left( \frac{h}{2} \right) - T_{m -
1}(h)}{4^{m} - 1}
\end{cases} ⎩ ⎨ ⎧ T 0 ( h ) T m ( h ) = T ( h ) = h f ( x + 2 h ) − f ( x − 2 h ) = 4 m − 1 4 m T m − 1 ( 2 h ) − T m − 1 ( h )
利用数值积分做数值微分
n n n [ a , b ] \lbrack a,b\rbrack [ a , b ] h = b − a n h = \frac{b - a}{n} h = n b − a f ( x i + 1 ) − f ( x i − 1 ) = ∫ x i − 1 x i + 1 f ′ ( x ) d x f\left( x_{i + 1} \right) - f\left( x_{i - 1}
\right) = \int_{x_{i - 1}}^{x_{i +
1}}f^{^{\prime}}(x)dx f ( x i + 1 ) − f ( x i − 1 ) = ∫ x i − 1 x i + 1 f ′ ( x ) d x
特征值
A x = λ x Ax = \lambda x A x = λ x
占优特征值与占优特征向量
如果A A A λ i \lambda_{i} λ i λ i \lambda_{i} λ i
幂法
x T A x = x T x λ ⟹ λ = x T A x x T x x^{T}Ax = x^{T}x\lambda \Longrightarrow
\lambda = \frac{x^{T}Ax}{x^{T}x} x T A x = x T x λ ⟹ λ = x T x x T A x
被成为 Rayleigh 商。给定特征向量近似,Rayleigh 商是最优近似。
具体方法:
给定初始向量x 0 x_{0} x 0
迭代第i i i u i − 1 = x i − 1 ∥ x i − 1 ∥ , λ i = u i − 1 T A u i − 1 , x i = A u i − 1 u_{i - 1} = \frac{x_{i - 1}}{\| x_{i -
1}\|},\lambda_{i} = u_{i - 1}^{T}Au_{i - 1},x_{i} = Au_{i -
1} u i − 1 = ∥ x i − 1 ∥ x i − 1 , λ i = u i − 1 T A u i − 1 , x i = A u i − 1
最后得到的u n = x n ∥ x n ∥ u_{n} = \frac{x_{n}}{\|
x_{n}\|} u n = ∥ x n ∥ x n
对于几乎所有的初始向量,幂法都会线性收敛到最大特征值λ 1 \lambda_{1} λ 1 ∣ λ 2 λ 1 ∣ |\frac{\lambda_{2}}{\lambda_{1}}| ∣ λ 1 λ 2 ∣
反幂法与 Rayleigh 商迭代
A − 1 A^{- 1} A − 1 A A A A − 1 A^{- 1} A − 1 A A A
在求出最小特征值后,可以通过对A − λ I A - \lambda
I A − λ I
若已知一个近似的特征值λ ^ \hat{\lambda} λ ^ A − λ ^ A
- \hat{\lambda} A − λ ^
QR 方法:略
常微分方程
{ y ′ ( t ) = f ( t , y ( t ) ) y ( t 0 ) = y 0 \begin{cases}
y^{^{\prime}}(t) = f\left( t,y(t) \right) \\
y\left( t_{0} \right) = y_{0}
\end{cases} { y ′ ( t ) = f ( t , y ( t ) ) y ( t 0 ) = y 0
Lipschitz 条件
∀ t ∈ [ a , b ] , y 1 , y 2 ∈ R \forall t \in \lbrack
a,b\rbrack,y_{1},y_{2} \in R ∀ t ∈ [ a , b ] , y 1 , y 2 ∈ R ∣ f ( t , y 1 ) − f ( t , y 2 ) ∣ ≤ L ∣ y 1 − y 2 ∣ |f\left( t,y_{1} \right) - f\left( t,y_{2} \right)|
\leq L|y_{1} - y_{2}| ∣ f ( t , y 1 ) − f ( t , y 2 ) ∣ ≤ L ∣ y 1 − y 2 ∣
若f ( t , y ) f(t,y) f ( t , y ) [ a , b ] × R \lbrack a,b\rbrack \times R [ a , b ] × R y y y [ a , b ] \lbrack a,b\rbrack [ a , b ]
适定性
若f ( t , y ) f(t,y) f ( t , y ) [ a , b ] × R \lbrack a,b\rbrack \times R [ a , b ] × R y y y Y ( t ) Y(t) Y ( t ) Z ( t ) Z(t) Z ( t ) Y ( t 0 ) Y\left( t_{0} \right) Y ( t 0 ) Z ( t 0 ) Z\left( t_{0} \right) Z ( t 0 ) ∣ Y ( t ) − Z ( t ) ∣ ≤ ∣ Y ( t 0 ) − Z ( t 0 ) ∣ exp ( L ∣ t − t 0 ∣ ) |Y(t) - Z(t)| \leq |Y\left( t_{0} \right) - Z\left(
t_{0} \right)|\exp(L|t - t_{0}|) ∣ Y ( t ) − Z ( t ) ∣ ≤ ∣ Y ( t 0 ) − Z ( t 0 ) ∣ exp ( L ∣ t − t 0 ∣ )
显式 Euler 方法
向前差分:f ( t i , y i ) = y ′ ( t i ) ≈ y ( t i + 1 ) − y ( t i ) h ≈ y i + 1 − y i h ⇒ y i + 1 = y i + h ⋅ f ( t i , y i ) f\left( t_{i},y_{i} \right) =
y^{^{\prime}}\left( t_{i} \right) \approx \frac{y\left( t_{i + 1} \right) -
y\left( t_{i} \right)}{h} \approx \frac{y_{i + 1} - y_{i}}{h}
\Rightarrow y_{i + 1} = y_{i} + h \cdot f\left( t_{i},y_{i}
\right) f ( t i , y i ) = y ′ ( t i ) ≈ h y ( t i + 1 ) − y ( t i ) ≈ h y i + 1 − y i ⇒ y i + 1 = y i + h ⋅ f ( t i , y i )
稳定性:满足 Lipschitz 条件时,∣ y i − z i ∣ ≤ ∣ y 0 − z 0 ∣ exp ( L ∣ t i − t 0 ∣ ) |y_{i} -
z_{i}| \leq |y_{0} - z_{0}|\exp(L|t_{i} - t_{0}|) ∣ y i − z i ∣ ≤ ∣ y 0 − z 0 ∣ exp ( L ∣ t i − t 0 ∣ )
局部截断误差:(记M =
\max|y^{^{\prime}}^{\prime}(t)| \begin{aligned}
\tau_{i + 1} = |y\left( t_{i + 1} \right) - y_{i + 1}| & = |y\left(
t_{i} + h \right) - y\left( t_{i} \right) - hf\left( t_{i},y\left( t_{i}
\right) \right)| \\
& = |hy^{^{\prime}}\left( t_{i} \right) +
\frac{h^{2}}{2}y^{^{\prime}}^{\prime}(t) + \ldots - hy^{^{\prime}}\left( t_{i}
\right)| \\
& = O\left( h^{2} \right) \leq \frac{M}{2}h^{2}
\end{aligned}
称此方法具有一阶精度。
隐式 Euler 方法
向后差分:f ( t i + 1 , y i + 1 ) = y ′ ( t i + 1 ) ≈ y ( t i + 1 ) − y ( t i ) h ≈ y i + 1 − y i h ⇒ y i + 1 = y i + h ⋅ f ( t i + 1 , y i + 1 ) f\left( t_{i + 1},y_{i + 1}
\right) = y^{^{\prime}}\left( t_{i + 1} \right) \approx \frac{y\left( t_{i
+ 1} \right) - y\left( t_{i} \right)}{h} \approx \frac{y_{i + 1} -
y_{i}}{h} \Rightarrow y_{i + 1} = y_{i} + h \cdot f\left( t_{i + 1},y_{i
+ 1} \right) f ( t i + 1 , y i + 1 ) = y ′ ( t i + 1 ) ≈ h y ( t i + 1 ) − y ( t i ) ≈ h y i + 1 − y i ⇒ y i + 1 = y i + h ⋅ f ( t i + 1 , y i + 1 )
由于只有y i y_{i} y i F ( x ) = x − y i − h f ( t i + 1 , x ) = 0 F(x) = x - y_{i} - hf\left( t_{i + 1},x \right) =
0 F ( x ) = x − y i − h f ( t i + 1 , x ) = 0
绝对稳定性:考虑y ′ ( t ) = λ y ( t ) y^{^{\prime}}(t) = \lambda
y(t) y ′ ( t ) = λ y ( t ) ∣ 1 + h λ ∣ ≤ 1 |1 +
h\lambda| \leq 1 ∣1 + hλ ∣ ≤ 1 ∣ 1 − h λ ∣ ≥ 1 |1 - h\lambda| \geq 1 ∣1 − hλ ∣ ≥ 1
全局截断误差
满足 Lipschitz 条件时,单步 ODE 求解为y i y_{i} y i τ i ≤ C h k + 1 \tau_{i} \leq Ch^{k +
1} τ i ≤ C h k + 1 e i ≤ C h k L ( exp ( L ( t i − t 0 ) ) − 1 ) e_{i} \leq
\frac{Ch^{k}}{L}\left( \exp(L\left( t_{i} - t_{0} \right)) - 1
\right) e i ≤ L C h k ( exp ( L ( t i − t 0 ) ) − 1 ) O ( h k + 1 ) O\left( h^{k
+ 1} \right) O ( h k + 1 ) k k k
梯形法
y i + 1 − y i ≈ ∫ t i t i + 1 f ( t , y ( t ) ) d t ≈ h 2 ( f ( t i , y i ) + f ( t i + 1 , y i + 1 ) ) y_{i + 1} - y_{i} \approx
\int_{t_{i}}^{t_{i + 1}}f\left( t,y(t) \right)dt \approx
\frac{h}{2}\left( f\left( t_{i},y_{i} \right) + f\left( t_{i + 1},y_{i +
1} \right) \right) y i + 1 − y i ≈ ∫ t i t i + 1 f ( t , y ( t ) ) d t ≈ 2 h ( f ( t i , y i ) + f ( t i + 1 , y i + 1 ) )
隐式方法;二阶方法。
显式:先用显式 Euler 方法预测y i + 1 y_{i +
1} y i + 1 y i + 1 = y i + h 2 ( f ( t i , y i ) + f ( t i + 1 , y i + h f ( t i , y i ) ) ) y_{i + 1} = y_{i}
+ \frac{h}{2}\left( f\left( t_{i},y_{i} \right) + f\left( t_{i +
1},y_{i} + hf\left( t_{i},y_{i} \right) \right) \right) y i + 1 = y i + 2 h ( f ( t i , y i ) + f ( t i + 1 , y i + h f ( t i , y i ) ) )
也可以写成s 1 = f ( t i , y i ) s 2 = f ( t i + 1 , y i + h s 1 ) y i + 1 = y i + h 2 ( s 1 + s 2 ) \begin{aligned}
s_{1} & = f\left( t_{i},y_{i} \right) \\
s_{2} & = f\left( t_{i + 1},y_{i} + hs_{1} \right) \\
y_{i + 1} & = y_{i} + \frac{h}{2}\left( s_{1} + s_{2} \right)
\end{aligned} s 1 s 2 y i + 1 = f ( t i , y i ) = f ( t i + 1 , y i + h s 1 ) = y i + 2 h ( s 1 + s 2 )
形如此类的方法称为二阶 Runge-Kutta 方法。
Runge-Kutta 方法
一般地,二阶显式 Runge-Kutta 方法为:s 1 = f ( t i , y i ) s 2 = f ( t i + a h , y i + a h s 1 ) y i + 1 = y i + h ( b 1 s 1 + b 2 s 2 ) \begin{aligned}
s_{1} & = f\left( t_{i},y_{i} \right) \\
s_{2} & = f\left( t_{i} + ah,y_{i} + ahs_{1} \right) \\
y_{i + 1} & = y_{i} + h\left( b_{1}s_{1} + b_{2}s_{2} \right)
\end{aligned} s 1 s 2 y i + 1 = f ( t i , y i ) = f ( t i + ah , y i + ah s 1 ) = y i + h ( b 1 s 1 + b 2 s 2 )
显式梯形方法:a = 1 , b 1 = b 2 = 1 2 a = 1,b_{1} = b_{2} =
\frac{1}{2} a = 1 , b 1 = b 2 = 2 1
局部截断误差:略
一阶条件:b 1 + b 2 = 1 , ∀ a b_{1} + b_{2} = 1,\forall
a b 1 + b 2 = 1 , ∀ a
二阶条件:b 1 + b 2 = 1 2 , a b 2 = 1 2 b_{1} + b_{2} =
\frac{1}{2},ab_{2} = \frac{1}{2} b 1 + b 2 = 2 1 , a b 2 = 2 1
三阶条件:不存在
中点法:a = 1 2 , b 1 = 0 , b 2 = 1 , y i + 1 = y i + h f ( t i + h 2 , y i + h 2 f ( t i , y i ) ) a = \frac{1}{2},b_{1} = 0,b_{2} =
1,y_{i + 1} = y_{i} + hf\left( t_{i} + \frac{h}{2},y_{i} +
\frac{h}{2}f\left( t_{i},y_{i} \right) \right) a = 2 1 , b 1 = 0 , b 2 = 1 , y i + 1 = y i + h f ( t i + 2 h , y i + 2 h f ( t i , y i ) )
更高阶的略
多步法
f ( t i + 1 , y i + 1 ) = y ′ ( t i + 1 ) ≈ y ( t i + 2 ) − y ( t i ) 2 h ≈ y i + 2 − y i 2 h ⇒ y i + 2 = y i + 2 h f ( t i + 1 , y i + 1 ) f\left( t_{i + 1},y_{i + 1} \right) =
y^{^{\prime}}\left( t_{i + 1} \right) \approx \frac{y\left( t_{i + 2}
\right) - y\left( t_{i} \right)}{2h} \approx \frac{y_{i + 2} -
y_{i}}{2h} \Rightarrow y_{i + 2} = y_{i} + 2hf\left( t_{i + 1},y_{i + 1}
\right) f ( t i + 1 , y i + 1 ) = y ′ ( t i + 1 ) ≈ 2 h y ( t i + 2 ) − y ( t i ) ≈ 2 h y i + 2 − y i ⇒ y i + 2 = y i + 2 h f ( t i + 1 , y i + 1 )
初值条件为y 0 , y 1 y_{0},y_{1} y 0 , y 1
一般地,初值条件给出y 0 , y 1 , … , y k − 1 y_{0},y_{1},\ldots,y_{k
- 1} y 0 , y 1 , … , y k − 1 k k k ∑ j = 0 s α j y i + j = h ∑ j = 0 s β j f ( t i + j , y i + j ) \sum_{j = 0}^{s}\alpha_{j}y_{i + j} = h\sum_{j =
0}^{s}\beta_{j}f\left( t_{i + j},y_{i + j} \right) j = 0 ∑ s α j y i + j = h j = 0 ∑ s β j f ( t i + j , y i + j )
方程组与高阶方程
{ y 1 ′ = f 1 ( t , y 1 , y 2 , … , y n ) y 2 ′ = f 2 ( t , y 1 , y 2 , … , y n ) … y n ′ = f n ( t , y 1 , y 2 , … , y n ) \begin{cases}
y_{1}^{^{\prime}} = f_{1}\left( t,y_{1},y_{2},\ldots,y_{n} \right) \\
y_{2}^{^{\prime}} = f_{2}\left( t,y_{1},y_{2},\ldots,y_{n} \right) \\
\ldots \\
y_{n}^{^{\prime}} = f_{n}\left( t,y_{1},y_{2},\ldots,y_{n} \right)
\end{cases} ⎩ ⎨ ⎧ y 1 ′ = f 1 ( t , y 1 , y 2 , … , y n ) y 2 ′ = f 2 ( t , y 1 , y 2 , … , y n ) … y n ′ = f n ( t , y 1 , y 2 , … , y n )
每个变量都需要自己的初值。
对于高阶方程y ( n ) = f ( t , y , y ′ , … , y ( n − 1 ) ) y^{(n)} = f\left(
t,y,y^{^{\prime}},\ldots,y^{(n - 1)} \right) y ( n ) = f ( t , y , y ′ , … , y ( n − 1 ) ) y 1 = y , y 2 = y ′ , … , y n = y n − 1 y_{1} = y,y_{2} = y^{^{\prime}},\ldots,y_{n} = y^{n -
1} y 1 = y , y 2 = y ′ , … , y n = y n − 1 { y 1 ′ = y 2 y 2 ′ = y 3 … y n − 1 ′ = y n y n ′ = f ( t , y 1 , y 2 , … , y n ) \begin{cases}
y_{1}^{^{\prime}} = y_{2} \\
y_{2}^{^{\prime}} = y_{3} \\
\ldots \\
y_{n - 1}^{^{\prime}} = y_{n} \\
y_{n}^{^{\prime}} = f\left( t,y_{1},y_{2},\ldots,y_{n} \right)
\end{cases} ⎩ ⎨ ⎧ y 1 ′ = y 2 y 2 ′ = y 3 … y n − 1 ′ = y n y n ′ = f ( t , y 1 , y 2 , … , y n )
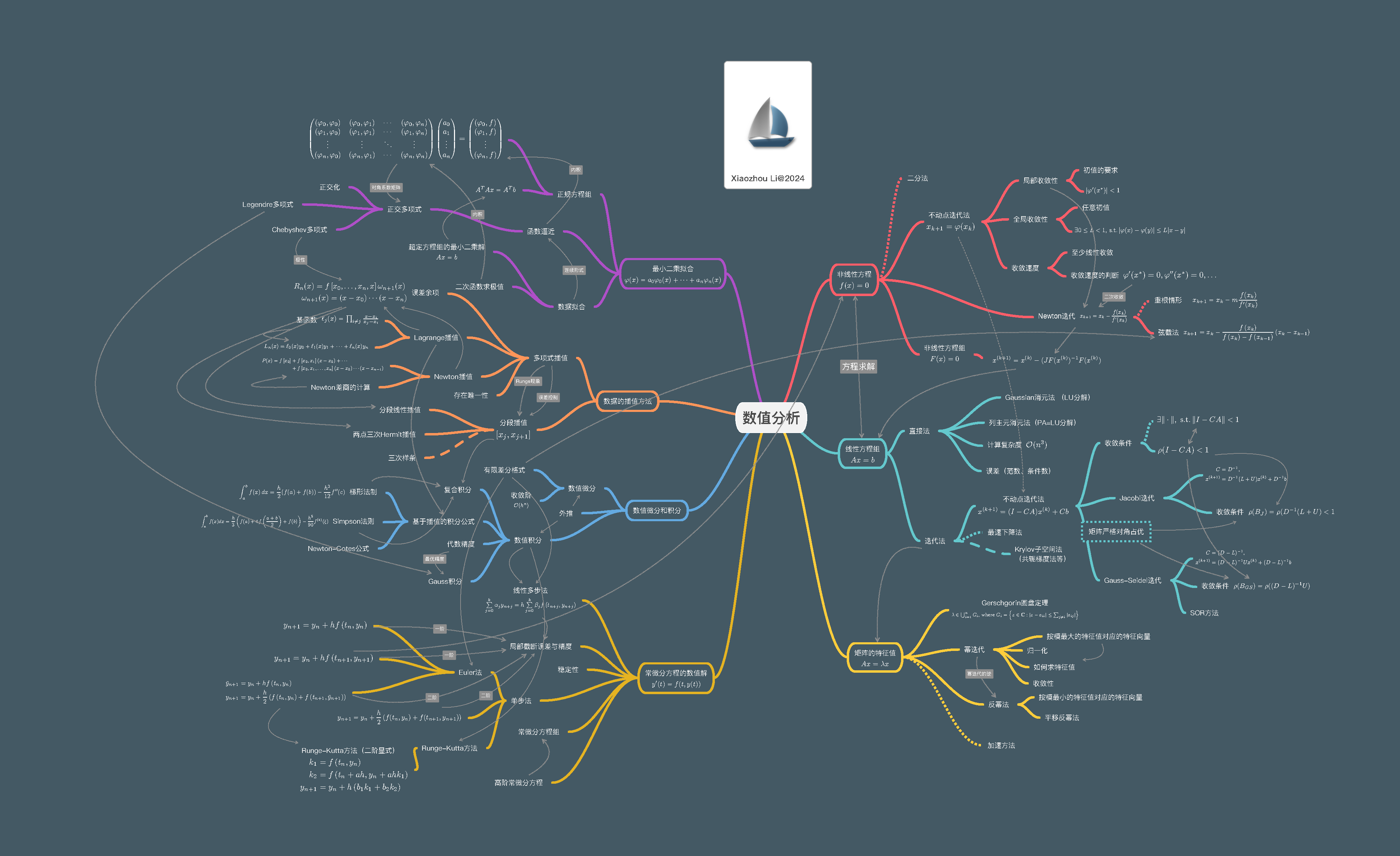 这里可以下载PDF版本
这里可以下载PDF版本