前置知识
线性组合:对于一组向量 a1,…,an,若存在一组标量 c1,…,cn 使 a=∑ciai,则称 a 可由这组向量线性表示,且 c1,…,cn 称为 a 关于 a1,…,an 的线性组合系数。
线性相关、线性无关:对于一组向量,若能够由非全为零的系数线性表示为零向量则称为线性相关,否则称为线性无关。
张成子空间:由一组向量线性组合得到的向量集合称为张成子空间。
基、维数:若向量组线性无关且张成整个空间,则称为基,此向量组的向量个数称为维数。
秩:矩阵的秩是指矩阵的列空间的维数。
保秩运算:TODO
矩阵的逆及其计算:若 A
为可逆矩阵,则 A−1 存在,且 AA−1=A−1A=I。
线性方程组 Ax=b
解的存在性理论:
解的表达方式:
范数:向量空间中的范数是一个函数,其满足非负性、齐次性、三角不等式
内积:向量空间中的内积是一个函数,其满足对称性、线性性、正定性
各种范数不等式:
1-范数:∥x∥1=∑∣xi∣
2-范数:∥x∥2=∑xi2
无穷范数:∥x∥∞=max∣xi∣
线性变换:一个向量空间到另一个向量空间的映射,且满足线性性质(保持加法和数乘)。
相似变换:若存在一个可逆矩阵 P
使得 B=P−1AP,则称 A 和 B
相似。
正交矩阵:若 ATA=I,则称
A 为正交矩阵。
对称矩阵:若 AT=A,则称
A 为对称矩阵。
正交投影算子:TODO
值域、零空间及其关系:
正定二次型及其性质:若对于任意非零向量 x,都有 xTAx>0,则称 A
为正定二次型。
矩阵导出范数:对于给定的向量范数 ∥⋅∥,矩阵 A
的导出范数定义为 ∥A∥=x=0sup∥x∥∥Ax∥=∥x∥=1sup∥Ax∥。
瑞利不等式:对于一个对称矩阵 A,有 λmin≤xTxxTAx≤λmax。
线搜索
求解单峰的一元单值函数在闭区间上的最小值。
黄金分割法
将区间 [a,b]
分成三份,切分点(比例)为 [0,λ,μ,1],其中 λ=1−μ,1μ=μλ,每次选择 [0,μ] 或 [λ,1]
作为新的区间,且只需要计算一个新的切分点。
计算可得 λ=25−1≈0.618,μ=1−λ≈0.382。
记第 k 步时两侧区间的长度占比为
ρk,那么满足 ρk+1(1−ρk)=1−2ρk 时,其压缩率为 ∏1−ρk。当 ρk=23−5 时,则为上面提到的黄金分割点,而若ρk=1−FN−k+2FN−k+1(其中 Fi
为斐波那契数列)时,其压缩率为 FN+11,总压缩比比黄金分割法更小。
二分法
将区间 [a,b]
分成两份,每次选择中点 c=2a+b 作为新的区间的一端,通过 f′(c) 的符号来确定新的区间。
需要一阶导数,每一步的压缩比为 21。
牛顿法、割线法
二阶泰勒逼近:q(x)=f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2
取 q(x)
的极小值点作为下一个迭代点,即 q′(xk+1)=0⇒xk+1=xk−f′′(xk)f′(xk)。
当 f′′(xk)>0 时,牛顿法可以正常运行;如果在一些点处 f′′(xk)<0,则可能会出现收敛到极大点的情况。
割线法是牛顿法的一种变形,即用 f′′(xk)≈xk−xk−1f′(xk)−f′(xk−1)
来代替二阶导数。此方法需要两个初始点,但只需要一阶导数。
这两种方法还可以用于计算 g(x)=0
的根(q(xk+1)=0⇒xk+1=xk−g′(xk)g(xk)),也被称为牛顿割线法。
信赖域
TODO
无约束优化
通用格式:xk+1=xk+αkpk,其中 pk
为搜索方向,αk 为步长。
梯度下降法
搜索方向:pk=−∇f(xk)
最速下降法:αk= argminα≥0f(xk+αpk)
对于最速下降法,只要 ∇f(xk)=0,则 f(xk+1)<f(xk)。
牛顿法
将 f:Rn→R 在 xk
处进行二阶泰勒展开,得到 q(x)=f(xk)+∇f(xk)⊤(x−xk)+21(x−xk)⊤H(xk)(x−xk),其中 H(xk) 为 f 在 xk 处的海森矩阵。若 H(xk) 正定,则 q(x) 有唯一极小值点,即 xk+1=xk−H(xk)−1∇f(xk)
实际求解时,可以用 H(xk)pk=−∇f(xk) 来求解 pk,然后用 xk+1=xk+pk 来求解 xk+1。
共轭梯度法
共轭方向
Q 是一个对称实矩阵,若 pi⊤Qpj=0(i=j),则称 p1,…,pn 为 Q 关于 Q
共轭。
克莱姆-施密特过程构造共轭方向
给定一组 Rn
的线性无关向量 a1,…,an,可以通过以下过程得到一组关于对称正定矩阵
Q 共轭的向量 p1,…,pn:
p1=a1
pk+1=ak+1−∑i=1k(ak+1⊤Qpi)pi⊤Qpipi
矩阵特征值分解构造共轭方向
若 Q 为对称正定矩阵,且 Q=PΛP−1,则 pi=Pei 为 Q 关于 Q
共轭的向量。
共轭梯度法的步长与方向的推导
设 x∗−x0=∑i=0n−1βidi,两端同时乘以 dk⊤Q 可以得到 dk⊤Q(x∗−x0)=βkdk⊤Qdk(共轭的性质),因此 βk=dk⊤Qdkdk⊤Q(x∗−x0)
考虑第 k 步:x∗−x0=x∗−xk+(xk−x0)⇒dk⊤Q(x∗−x0)=dk⊤Q(x∗−xk)
由于 ∇f(x)=Qx−b,∇f(xk)=∇f(xk)−∇f(x∗)=Q(xk−x∗),则综合这两个子式可以得到 dk⊤Q(x∗−x0)=dk⊤Q(x∗−xk)=dk⊤(−∇f(xk)),即 βk=dk⊤Qdk−dk⊤∇f(xk)
考虑到 dk 一般通过迭代得到。dk 需要满足 与之前的 di 宫娥 与 dk= span(dk−1,∇f(xk))
两个条件(后者的原因可能就是“共轭梯度法”这个名字的来源吧),因此设 dk=βkdk−1−∇f(xk),因为共轭,有 dk−1⊤Qdk=βkdk−1⊤Qdk−1−dk−1⊤Q∇f(xk)⇒βk=…
拟牛顿法
在牛顿法中 xk=xk−1−H(xk−1)−1∇f(xk−1)
中,每一步都要计算 H(xk−1)−1,而拟牛顿法通过近似 H(xk−1)
或者它的逆来减少计算量,即 Bk≈H(xk−1) 或 Hk≈H(xk−1)−1。
f′′(xk)≈xk−xk−1f′(xk)−f′(xk−1)⇒f′(xk−1)≈f′(xk)+f′′(xk)(xk−1−xk)
记 Δgk=∇f(xk−1)−∇f(xk),Δxk=xk−1−xk(好扭曲的符号……),则上式简记为 (∇2f(xk))−1Δgk−1=Δxk−1,即 HkΔgk−1=Δxk−1。
通常希望 Hk
满足:对称正定、迭代计算量少、近似效果好。
SR1
{Hk+1Δgk=ΔxHk+1=Hk+auu⊤
代入得 (Hk+auu⊤)Δgk=Δxk=HkΔgk+auu⊤Δgk,即 au⊤Δgku=Δxku−HkΔgku。注意到 au⊤Δgk 是一个标量,不妨让它等于 1,则 u 与
a 依次可以解出。
公式太长,这里不放。
DFP
思想和上面类似,只不过变成了秩二修正,即 Hk+1=Hk+auu⊤+bvv⊤。
同样代入得到 au⊤Δgku+bv⊤Δgkv=Δxk−HkΔgk
一个简单的解为 u=Δxk,v=HkΔgk。
公式太长,还是不放。
BFGS
思想和上面类似,只不过变成了估计 ∇2f(xk),即 Bk+1=Bk+auu⊤+bvv⊤。
这下代入的应该是 BkΔxk=Δgk 了,即 au⊤Δxku+bv⊤Δxkv=Δgk−BkΔxk
与 DFP 非常对称。
Sherman-Morrison 公式
对于一个矩阵 A,若 A+uv⊤ 可逆,则有 (A+uv⊤)−1=A−1−1+v⊤A−1uA−1uv⊤A−1。
线性规划
标准型与松弛
minimize s.t. c⊤xAx=b≥0x≥0
化标准型方法:
maxf(x)⇒min−f(x)
x≤c⇒x+x′=c,x′≥0 (松弛)
ax=b<0⇒−ax=−b
x∈R⇒x=x′−x′′,x′,x′′≥0
(非负拆分)
设A∈Rm×n,其中m<n,于是进行列重排,使得A=[B,D],B∈Rm×m,于是存在一个解 x⊤=[B−1b;0],被称为基本解; B
的列被称为基本列,xB=B−1b
被称为基本变量。
注:若 xB
中有零值,则被称为退化的基本解。若某个可行解为(退化的)基本解,则称为(退化的)基本可行解。
单纯形法
基本思想:从一个基本可行解出发,通过改变基本变量,使得目标函数值逐渐减小,直到找到最优解。
当将 A 划分为 [B ∣ D]
后,目标函数值就可以表达为 z=cB⊤B−1b+(cD⊤−cB⊤B−1D)xD,其中定义 rD=cD⊤−cB⊤B−1D。由于 x≥0,因此若 rD≥0,则有最优解 x=[B−1b;0],否则将 rD
中的一个负值对应的列加入基本列,然后通过高斯消元法来求解新的基本解。
单纯形法的矩阵形式
(BcB⊤DcD⊤b0)⇒(I0B−1DcD⊤−cB⊤B−1DB−1b−cB⊤B−1b)=(I0B−1DrD⊤B−1b−z0)
转轴元素的选取
在选好列 l 后,由于 bi′=bi−aklbkail,所以希望 aklbk 最小。
初始解的选择——二阶段法
minc⊤x⇒miny1+…+ym [A ∣ I][x;y]=b,x,y≥0
若这个问题的最优解对应函数值为 z>0,则原问题无解
若解中存在 yi>0,则
若解中不存在 yi>0,则将
yi
所在列删去,直至得到一个原问题的基本可行解,此时再替换 c
大 M 法
⎩⎨⎧minc⊤xAx=bx≥0⇒⎩⎨⎧minc⊤x+M∑yiAx+y=bx,y≥0
将 M
代入一个无穷大的数处理即可。
具体在应用这些方法时,只需要能够构造出可行解即可,即:在 A 中有只包含 1 个 1 的列时,不需要严格构造 m 个 y。
整数规划
割平面法
原理:通过增加约束条件,把由单纯形法得到的非整数解从可行集中去除掉。新增的约束条件不去除可行集中的整数解。不断增加约束条件,直到得到一个整数最优解。
分支定界法
原理:将整数规划问题松弛,若解包含非整数分量 xi=x∗,则分为两个问题:xi≤⌊x∗⌋ 与 xi≥⌊x∗⌋+1,然后递归求解。
约束优化
等式约束
minf(x) s.t. h(x)=0
其中 x∈Rn,f:Rn→R,h:Rn→Rm,m≤n
正则点:若 hi(x∗)=0,∇hi(x∗) 线性无关,则 x∗ 为正则点。x∗ 为正则点 ⇔R(∇h(x∗))=m
切线空间 T(x∗)={y:∇h(x∗)⊤y=0},法线空间
N(x∗)= span(∇h(x∗))
Lagrange 函数
选择点 x∗ 使得 h(x∗)=0,∇h(x∗)=0,过 x∗
的水平集 x(t),t∈(a,b) 有 x∗=x(t∗),∀t,h(x(t))=0,则 dtdh(x(t))=(∇h(x))⊤x˙(t)=0。若 x∗ 为 f(x) 在 {x:h(x)=0} 上的极小点,则同理可得 ∇f(x∗) 与 x˙(t) 也正交。
(一阶必要条件)综上:若 x∗ 为等式约束的极值点,则 ∇f(x∗) 与 ∇h(x∗) 平行,即
∃λ∗ s.t. ∇f(x∗)+(λ∗)⊤∇h(x∗)=0,h(x∗)=0
(Lagrange 函数)定义 l(x;λ)=f(x)+λ⊤h(x)
则一阶的两个必要条件可以写成 ∇l(x∗;λ∗)=0
(二阶必要条件)若正则点 x∗ 为等式约束的极小点,则存在 λ∗ 使得一阶条件满足且 ∇2l(x∗;λ∗) 在切线空间 T(x∗) 上半正定(∀y∈T(x∗),y⊤∇2l(x∗;λ∗)y≥0)
不等式约束
minf(x) s.t. h(x)=0,g(x)≤0
其中 x∈Rn,f:Rn→R,h:Rn→Rm,g:Rn→Rp,m≤n
积极/非积极约束、正则点
对于一个不等式约束 gi(x)≤0,若在 x∗ 处 gi(x∗)=0,则称 gi(x∗) 为积极约束;若
gi(x∗)<0,则称 gi(x∗) 为非积极约束。
等式约束总是积极约束。
若 x∗ 满足所有约束条件 J(x∗)≜{j:gj(x∗)=0} 如果 ∇hi(x∗),∇gj(x∗),1≤j≤m,j∈J(x∗) (所有积极约束)线性无关,则称 x∗ 为正则点。
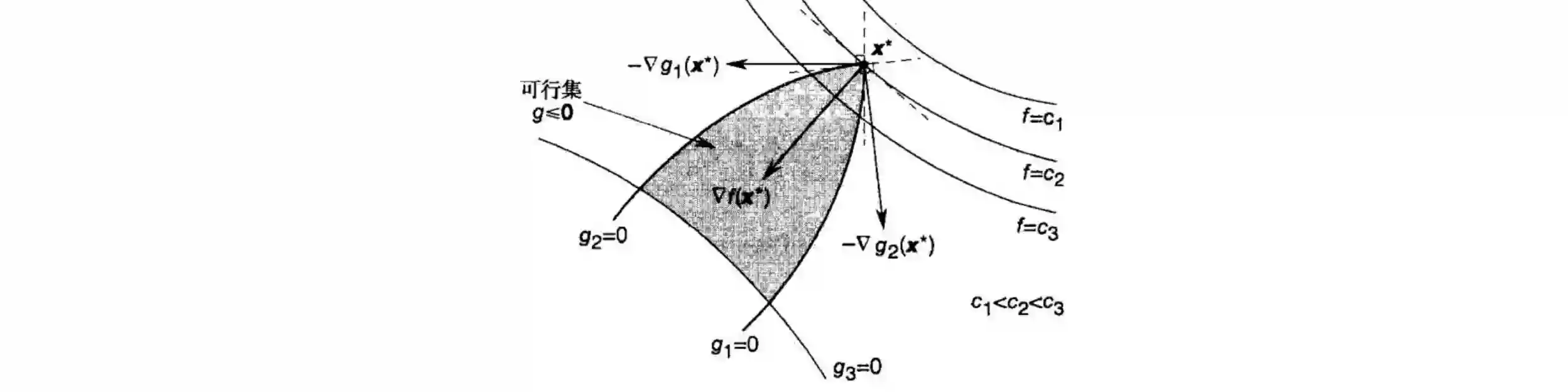
KKT 条件
minf(x) s.t. h(x)=0,g(x)≤0
原始可行性:h(x∗)=0,g(x∗)≤0
对偶可行性:μ∗≥0
互补松弛条件:μ∗g(x∗)=0
原始最优性:∇f(x∗)+(λ∗)⊤∇h(x∗)+(μ∗)⊤∇g(x∗)=0
注意 μ⋛0 与 g(x)⋛0
对偶可行性
当约束条件为 gj(x)≤0
时,可行集的方向为 −∇gj(x),因此要使得 x∗
为最优解,需要 ∇f(x∗)=−∑μj∗∇gj(x∗),μ∗≥0
互补松弛条件
μjgj(x∗)=0 说明了对于每个约束:
二阶必要条件
L(x,λ,μ)=∇2f(x)+λ⊤∇2h(x)+μ⊤∇2g(x)
若 x∗
为正则点,则极小值的二阶必要条件为:存在 λ∗,μ∗ 使得在满足一阶 KKT
条件的情况下,对于所有 y∈T(x∗) 有 y⊤L(x∗,λ∗,μ∗)y≥0
拉格朗日对偶
l(x;λ,μ)=f(x)+λ⊤h(x)+μ⊤g(x)
原问题为 minf(x) s.t. h(x)=0,g(x)≤0,因此 l(x;λ,μ)≤f(x),代入最优解 x∗
有 l(x∗;λ∗,μ∗)≤f(x∗),自然有 maxl(x∗;λ∗,μ∗)≤f(x∗),因此可以定义拉格朗日对偶函数 g(λ,μ)=maxl(x;λ,μ)
弱对偶性
由上面的推导可知,g(λ∗,μ∗)≤f(x∗),这被称为弱对偶性。
最大值中的最小值大于等于最小值中的最大值
强对偶性
若可行解 x∗,λ∗,μ∗ 满足 g(λ∗,μ∗)=f(x∗),则 x∗
为原问题的最优解,λ∗,μ∗
为对偶问题的最优解,这被称为强对偶性。
拉格朗日函数 l(x;λ,μ)
存在鞍点当且仅当强对偶性成立。
Slater 条件:若存在一个 x 使得 h(x)=0,g(x)<0,则强对偶性成立。(反之不一定成立)
线性规划的例子
minc⊤xs.t. Ax=b,x≥0
得到 l(x;λ)=c⊤x+λ⊤(Ax−b),原始问题为 xminλmaxl(x;λ),对偶问题为
λmaxxminl(x;λ)。令
g(λ)=xminl(x;λ)=xmin((c⊤+λ⊤A)x−λ⊤b) 则对偶问题为 λmaxg(λ)。
因为 x≥0,所以如果 c⊤+λ⊤A 的某个分量为负,则
g(λ) 可以取到 −∞;因此需要 c⊤+λ⊤A≥0,此时 g(λ)=−λ⊤b,因此对偶问题为 λmax−λ⊤b s.t. c⊤≥−λ⊤A
或:λminλ⊤b s.t. λ⊤A≤c
凸优化
函数图像:epi(f)={[x;t]:x∈Ω,t≥f(x)}
凸函数:若 epi(f)
为凸集,则称 f 为凸函数
凸集:若对于任意 x,y∈C,0≤λ≤1,有 λx+(1−λ)y∈C,则称 C
为凸集
广义梯度:对于凸函数 f,定义
∇f(x)={g:f(y)≥f(x)+g⊤(y−x),∀y}(在 x
处能够“包住”整个函数的切线集合,类似全空间减去一个椎体)
保凸性质:线性组合、求上确界……
凸优化问题的性质
局部最优解 ⇔
全局最优解
全局极小条件:若 x∗
满足对任意可行方向 d,有 d⊤∇f(x∗)≥0,则 x∗
为全局极小点
拉格朗日条件、KKT 条件在凸优化问题中是充分条件
投影方法
约束问题 minf(x) s.t. x∈Ω 用无约束优化迭代格式 xk+1=xk+αkdk
来求解可能会导致迭代点不在可行域内,因此需要投影方法来保证迭代点在可行域内。
投影:设 Ω 为非空闭凸集,∀x∈Rn,定义其在
Ω 上的投影为 ∏(x)= argminz∈Ω∥x−z∥
投影方法:xk+1=∏(xk+αkdk)
简单集合的投影表达式
箱形约束:Ω={x∈Rn:l≤x≤u},则 ∏(x)= median(l,x,u)
球形约束:Ω={x∈Rn:∥x∥≤r},则 ∏(x)=min(1,∥x∥r)x
拉格朗日法
约束问题 minf(x) s.t. h(x)=0,g(x)≤0 的拉格朗日函数为 l(x;λ,μ)=f(x)+λ⊤h(x)+μ⊤g(x)
xk+1=xk−αk∇xl(xk;λk,μk)λk+1=λk+βkh(xk)μk+1=[μk+γkg(xk)]+
罚函数法
约束问题 minf(x) s.t. x∈Ω 等价于无约束问题 minf(x)+ιΩ(x),其中 ιΩ(x) 为指示函数,定义为 ιΩ(x)={0,+∞, if x∈Ω otherwise
一般使用 γP(x)
近似指示函数,其中 γ
称为罚因子,P(x) 称为罚函数。
罚函数一般满足:
约束优化的罚函数:
增广拉格朗日法
相当于 minf(x)+γ(∥h(x)∥2+∥g+(x)∥2) s.t. h(x)=0,g(x)≤0
增广拉格朗日函数:l(x;λ,μ,γ)=f(x)+λ⊤h(x)+μ⊤g(x)+γ(∥h(x)∥2+∥g+(x)∥2),μ≥0
迭代格式:
xk+1= argminxl(x;λk,μk,γ)
λk+1=λk+γh(xk)
μk+1=[μk+γg+(xk)]+
多目标优化(了解)
多目标优化:具有多个目标函数的优化问题,通常是多个目标函数之间存在矛盾,无法同时优化。
Pareto 最优解
定义:若 x∗ 为 Pareto
最优解,则不存在 x 使得 f(x)≤f(x∗) 且 f(x)=f(x∗)。
求解过程:维护一个 Pareto 集合,对任意候选解:
转换为单目标优化
线性加权法:f′(x)=c⊤f(x),c>0,但是 c
的选择是一个问题
极小极大法:f′(x)=imaxfi(x),但是分量函数需要兼容(即:单位一致),且可能f′(x)不可微分
范数法:若目标向量全部非负,则 f′(x)=∥f(x)∥2
转化为约束问题:选择一个 i,问题转化为 minfi(x) s.t. ∀j=i,fj(x)≤bj,需要先确定一个期望
unimplemented: 不确定的线性规划