随机事件和概率
随机事件
随机试验和随机事件
随机试验的特征:可重复性、结果明确性、不可预测性
随机事件:在一定条件下基于一定的试验目的进行试验,称试验中每一个可能发生也可能不发生的事情为随机事件,简称事件,用大写字母A,B,C,…表示。
若试验目的不同,则基本事件也可能不同。
必然事件记为 Ω,不可能事件记为
∅。
集合表示
基本事件对应一个单点集,所有基本事件 An 对应的单点集 {ωn} 的并集为样本空间
Ω={ω1,ω2,…,ωn},其中的每一个元素称为样本点。
若试验目的不同,基本事件可能不同,样本空间因此也可能不同。
集合运算
中心思想:若一次试验的结果 ω∈A,则称事件 A 发生,否则称事件
A 不发生。
事件的和:A∪B={ω ∣ ω∈A or ω∈B}
事件的交:A∩B(AB)={ω ∣ ω∈A and ω∈B}
事件的差:A−B={ω ∣ ω∈A and ω∈/B}
事件的关系
事件的运算律
交换律:A∪B=B∪A,A∩B=B∩A
结合律:A∪(B∪C)=(A∪B)∪C,A∩(B∩C)=(A∩B)∩C
分配律:A∩(B∪C)=(A∩B)∪(A∩C),A∪(B∩C)=(A∪B)∩(A∪C)
德摩根律:A∪B=A∩B,A∩B=A∪B
吸收律:A⊂B⇒A∪B=B,A∩B=A
概率
频率具有不确定性(是一个变量),但是随着试验次数的增加,频率会稳定于一个常数附近。
代数、可测空间、概率空间
对于样本空间 Ω,若 F 满足:
Ω∈F
A∈F⇒A∈F
A1,A2,…∈F⇒∪n=1∞An∈F
注:若 Ω 为有限集,则 Ω 的代数一定为 σ-代数。
注(勒贝格测度):TODO
当 F 为 σ-代数时,记 (Ω,F)
为可测空间,而对其中的 F
作为定义域的函数满足概率公理时,记 (Ω,F,P) 为概率(测度)空间。
概率的性质
事件 A 出现的概率记为 P(A),满足:
非负性:P(A)≥0
规范性:P(Ω)=1
可列可加性:若 A1,A2,… 两两互不相容,则 P(A1∪A2∪…)=P(A1)+P(A2)+…
性质有:
条件概率、乘法公式、全概率公式、贝叶斯公式
P(A∣B)=P(B)P(AB),P(B)>0
条件概率 P(⋅ ∣ B)
也是一种概率,满足概率的三个公理。
乘法公式:P(AB)=P(A∣B)P(B)=P(B∣A)P(A)
全概率公式:若 Bi 为 Ω 的一个可列划分,则 P(A)=∑P(A∣Bi)P(Bi) (常用于知因求果) 条件全概率公式:P(A∣D)=∑P(A∣Bi∩D)P(Bi∣D)
贝叶斯公式:(常用于知果求因)其中 Hi 为 Ω 的一个可列划分P(Hi∣E)=P(E)P(EHi)=∑jP(E∣Hj)P(Hj)P(E∣Hi)P(Hi)=P(Hi)∑jP(E∣Hj)P(Hj)P(E∣Hi) 其中 P(Hi) 被称为先验概率,P(Hi∣E)
被称为后验概率,最后的那个分数被称为调整因子。H 代表假设(Hyphothesis),E 代表证据(Evidence)。
独立性
若 P(A∣B)=P(A)⇔P(AB)=P(A)P(B),则称事件 A 和事件 B
相互独立。事件 A
发生的可能性大小不受事件 B
出现与否的影响。
若 A,B 独立,则 A,B,A,B
四个事件两两独立。
相互独立:若 P(A1A2⋯An)=P(A1)P(A2)⋯P(An),则称事件 A1,A2,⋯,An
相互独立(比两两独立更强)。
A={ 骰子 1 为奇数 },B={
骰子 2 为奇数 },C={ 骰子 1 与 骰子 2 均为奇数 },则 A,B,C
两两独立,但不相互独立。
随机变量
设 (Ω,F,P) 为概率空间
随机变量的定义
ξ(ω) 是定义在样本空间 Ω 上的实值函数,若对任意实数 x,集合 {ω:ξ(ω)≤x}∈F,则称 ξ(ω) 为随机变量。ξ(ω) 将样本点映射到实数上。
记 {ξ≤x}={ω:ξ(ω)≤x},注意这种记法这是一个样本点的集合。
为什么只要求 {ξ≤x}∈F:F 为
σ-代数,在此条件满足时,{ξ≥x}、{ξ<x}、{ξ>x}、{ξ=x} 等集合也在 F 中。
随机变量的分布函数
随机变量 ξ 的分布函数 F(x) 定义为 F(x)=P{ξ≤x}=P{ω:ξ(ω)≤x},注意 ≤ 符号。
分布函数的性质:
单调不减
有界性:0≤F(x)≤1,F(−∞)=0,F(+∞)=1
右连续性:F(x+0)=F(x)
若一个函数满足上述三个性质,则一定存在一个随机变量与之对应。
分布律
对于离散型随机变量,其分布函数为分布律,即P(ξ=xi)=pi,其中
pi 为概率,xi 为随机变量 ξ 可能取到的值。
概率密度函数
对于连续型随机变量,其分布函数为概率密度函数,即 f(x),满足 F(x)=∫−∞xf(t)dt。
对于连续型随机变量,分布函数 F(x)
是连续的(左、右连续均满足),还是绝对连续的(即:一致连续、几乎处处可导)。
不可能事件的概率为 0,但是概率为
0 的事件不一定是不可能事件。
常见分布
知道:常见分布的数学模型及应用场景
记住:常见分布的分布律、概率密度
概率密度函数的定义域为实数集。为简单起见,下方未定义的区域的概率密度为
0。
二项分布:B(n,p)
P(ξ=k)=Cnkpk(1−p)n−k,E(ξ)=np,D(ξ)=np(1−p)
来源:n 重伯努利试验中成功次数 ξ 的分布
泊松分布:P(λ)
P(ξ=k)=e−λk!λk,E(ξ)=λ,D(ξ)=λ
来源:B(n,nλ),n→∞,即 λ=npn 代表了单位时间内事件发生的次数(pn 为将单位时间分为 n
份后,每份内事件发生的概率,这里认为划分后的每份内事件只会发生一次)
实际问题中,
大量独立重复试验中,“稀有事件”出现的次数可认为服从泊松分布(n较大,pn较小)
几何分布
P(ξ=k)=(1−p)k−1p
来源:第 k 次成功发生的次数 ξ 的分布
负二项分布
P(ξ=k)=Ck−1n−1pn(1−p)k−n
来源:第 n 次成功发生的次数 ξ 的分布
均匀分布:U(a,b)
f(x)=b−a1,a≤x≤b,E(ξ)=2a+b,D(ξ)=12(b−a)2
指数分布:E(λ),λ>0
f(x)=λe−λx,x≥0,E(ξ)=λ−1,D(ξ)=λ−2(E=σ)
特点:无后效性(即:P(ξ>s+t ∣ ξ>s)=P(ξ>t))
来源:泊松过程中两次事件之间的时间间隔(失效率,越高越容易失效)
- 正态分布:N(μ,σ2)
f(x)=σ2π1e2σ2−(x−μ)2
N(0,1) 称为标准正态分布,其分布函数为
Φ(x)。对于任意正态分布 N(μ,σ2),其分布函数为
Φ(σx−μ)
Γ 分布:Γ(α,β)
f(x)=βαxα−1Γ(α)e−βx,x>0,E(ξ)=βα,D(ξ)=β2α
Γ(n,1) 为 n 阶指数分布,Γ(1,λ) 为参数为 λ 的指数分布
Γ(1,1) 为参数为 1 的指数分布
多维随机变量
如果 ξ,η 是定义在同一概率空间
(Ω,F,P)
上的两个随机变量,那么称 (ξ,η)
为二维随机变量。即一个样本点 ω
对应两个变量值 (ξ(ω),η(ω))。
联合分布函数、边缘分布函数
对于二维随机变量 (ξ,η),其联合分布函数 F(x,y) 定义为 F(x,y)=P{ξ≤x,η≤y}。
对于二维随机变量 (ξ,η),其边缘分布函数定义为 Fξ(x)=P{ξ≤x} 和
Fη(y)=P{η≤y}。
联合分布函数可以推导出边缘分布函数,如Fξ(x)=F(x,+∞)。
联合分布函数的性质:
单调不减:对一个单独的变量,另一个变量的值增大,概率不会减小。
有界性:0≤F(x,y)≤1,F(−∞,⋅)=F(⋅,−∞)=0,F(+∞,+∞)=1
右连续性:分别关于单独的变量右连续。
相容性:F(x2,y2)−F(x1,y2)−F(x2,y1)+F(x1,y1)≥0
与一维随机变量类似,若存在一个函数满足上述性质,则一定存在一个二维随机变量与之对应。
二维正态分布
(ξ,η)∼N(m1,σ12;m2,σ22;r),其中 m1,m2 分别为 ξ,η 的均值,σ1,σ2>0 分别为 ξ,η 的标准差,∣r∣<1 为相关系数。
若 (ξ,η)∼N(m1,σ12;m2,σ22;r),则 ξ∼N(m1,σ12),η∼N(m2,σ22)。但反之不一定成立。
相互独立性
若 P{ξ≤x,η≤y}=P{ξ≤x}P{η≤y},则称 ξ,η
相互独立。
等价条件:
联合分布函数 F(x,y)=Fξ(x)Fη(y)
联合分布律 pij=pi⋅p⋅j(若需要否定,则找到一个反例即可)
边缘分布函数 f(x,y)=fξ(x)fη(y) 在平面上除去面积为 0 的集合成立
条件分布
对于二维随机变量 (ξ,η),若
Fη(y)>0,则称 Fξ∣η(x ∣ y)=P{ξ≤x ∣ η=y}=Fη(y)F(x,y) 为 ξ 在给定 η=y 的条件下的分布函数。
同理,条件概率密度函数 fξ∣η(x ∣ y)=fη(y)f(x,y)。
独立性:若 ξ,η 相互独立,则
Fξ∣η(x ∣ y)=Fξ(x)。
随机变量函数的分布
若 ξ 是随机变量,则对连续函数
g(ξ) 来说也是一个随机变量。
和的分布(记住)
fX+Y(z)=FX+Y′(z)=∫−∞z∫−∞+∞f(x,z−x)dxdz=∫−∞+∞f(x,z−x)dx
分布函数法
对于 Y=g(X): FY(y)=P{g(X)≤y}=∫g(x)≤yf(x)dx⇒fY(y)=FY′(y)
随机变量的数字特征
期望:随机变量取值的平均值(集中点),记为 E(ξ)
方差:随机变量取值相对期望的偏离程度,记为 D(ξ)
相关系数:两个随机变量之间的线性相关程度,记为 ρ(ξ,η)
期望
E(ξ)=∫−∞+∞xdF(x)
要求绝对收敛,即 ∫−∞+∞∣x∣dF(x)<+∞。
对于随机变量函数 Y=g(X),E(Y)=E(g(X))=∫−∞+∞g(x)dF(x)。
TODO:特征函数与矩的关系
公式:
E(aξ+b)=aE(ξ)+b
E(∑aiξi)=∑aiE(ξi)
相互独立:E(∏ξi)=∏E(ξi)
方差与协方差
D(ξ)=E((ξ−E(ξ))2)=E(ξ2)−(E(ξ))2
(若 E(ξ2)
存在,则 E(ξ) 与 D(ξ) 一定存在)
Cov(ξ,η)=E((ξ−E(ξ))(η−E(η)))=E(ξη)−E(ξ)E(η)
公式:
D(aξ+b)=a2D(ξ),Cov(aξ,bη)=abCov(ξ,η)
D(ξ)=Cov(ξ,ξ)
D(ξ±η)=D(ξ)+D(η)±2Cov(ξ,η)
Cov(ξ1±ξ2,η)=Cov(ξ1,η)±Cov(ξ2,η)
协方差矩阵 Σ
的对角线元素为方差,非对角线元素为协方差;相关系数矩阵同理。
相关系数
ρ(ξ,η)=D(ξ)D(η)Cov(ξ,η)=Cov(ξ∗,η∗)≤1
相关系数是标准化随机变量的协方差。
当 ∣ρ∣=1
时,两个随机变量完全线性相关,即 ∃a,b s.t. P{η=a+bξ}=1。
当 ρ=0
时,两个随机变量没有线性相关性(但是可能有非线性相关性,因此不能说明两个随机变量相互独立)。
Chebyshev 不等式
P{∣ξ−E(ξ)∣≥ε}≤ε2D(ξ)
方差刻划了随机变量关于其数学期望的偏离程度,随机变量关于其数学期望的偏离程度比关于其它任何值的偏离程度都小!
Cauchy-Schwarz 不等式
(E(ξη))2≤E(ξ2)E(η2)
协方差矩阵中,有 bij2≤biibjj。
条件期望、方差
条件数学期望:E(ξ ∣ y)=E(ξ∣η=y)=∫−∞+∞xdFξ∣η(x ∣ y)
若使用 η 替换 y,则有实值函数 δ(y)=E(ξ ∣ y)。(一般也记 μ(x)=E(η ∣ x)),也是随机变量。(如:E(aξ+bη ∣ ψ)=aE(ξ ∣ ψ)+bE(η ∣ ψ))
若 ξ,η 相互独立,则 E(ξ ∣ η)=E(ξ)
E(E(ξ ∣ η))=E(ξ) (全期望公式)
E(g(η)ξ ∣ η)=g(η)E(ξ ∣ η)
E(g(η)⋅ξ)=E(E(g(η)ξ ∣ η))=E(g(η)E(ξ ∣ η))
E(c∣η)=c,其中
c 为常数
E(g(η))=E(g(η)⋅E(1 ∣ ψ))=E(E(g(η) ∣ ψ))
全数学期望公式:E(ξ)=∫E(ξ ∣ y)dFη(y)
矩
n 阶原点矩:E(ξn),n 阶绝对原点矩:E(∣ξ∣n)
n 阶中心矩:E((ξ−E(ξ))n),n 阶绝对中心矩:E(∣ξ−E(ξ)∣n)
多维正态随机变量
(ξ,η)∼N(m1,σ12;m2,σ22;r)
记:
E(ξη)=(m1m2)=M,Σ=(σ12rσ1σ2rσ1σ2σ22)
则 (ξ,η)∼N(M,Σ)
(ξ1,…,ξn) 服从多维正态分布,则以下命题等价:
ξ1,…,ξn
相互独立
ξ1,…,ξn
两两不相关
Σ 为对角矩阵
(ξ1,…,ξn) 服从 n 维正态分布 ⇔
它们的任何非零线性组合服从一维正态分布。
X=(ξ1,…,ξn) 服从 n
维正态分布,则对于任意矩阵 A,AX∼N(AM,AΣA⊤)。
特征函数
φ(t)=E(ejtξ)
φ(t1,…,tn)=E(ej(t1ξ1+…+tnξn))
性质:
一致连续、非负定
φ(t→)=φ(−t→)
∣φ(t→)∣≤φ(0→)=1
φ(t1,0)=φξ(t1)
一致连续、非负定、φ(0)=1
的函数一定是特征函数。
公式:
η=aξ+b⇒φη(t)=ejbtφ(at)
Z=aξ+bη+c⇒φZ(t)=ejctφ(at,bt),特别地,φξ+η(t)=φ(t,t)
独立性: ξ1,…,ξn
相互独立 ⇔ φ(t1,…,tn)=φξ1(t1)…φξn(tn)(二项分布的来源)
常见特征函数
二项分布:φ(t)=(1−p+pejt)n
泊松分布:φ(t)=exp(λ(ejt−1))
均匀分布:φ(t)=atsinat,U[a,−a]
正态分布:φ(t)=exp(−21t2),N(0,1)
特征函数与矩
若随机变量 ξ 的 n 阶矩存在,则 ξ 的特征函数的 k 阶导数存在且 E(ξk)=j−kφ(k)(0)。
D(ξ)=E(ξ2)−(E(ξ))2=−φ′′(0)−(φ′(0))2
反演公式
唯一性定理:分布函数恒等的充要条件是它们的特征函数恒等。
反演公式: F′(x)=f(x)=2π1∫−∞+∞e−jtxφ(t)dt
极限定理
以概率 1 收敛 > 依概率收敛 > 依分布收敛
依分布收敛 / 弱收敛
依分布收敛:对于分布函数列 {Fn(x)},若存在非降函数 F(x)
使得 n→∞limFn(x)=F(x) 对于 F(x)
的所有连续点成立,则称 {Fn(x)} 依分布收敛于 F(x),记为
Fn(x)⟶w/L/dF(x)。
收敛到的函数 F(x)
不一定是分布函数,如 F(x)=0。
连续性定理
连续性定理可用来确定随机变量序列的极限分布。
正极限定理:若随机变量列 {ξn} 依分布收敛于随机变量 ξ,则相应的特征函数列 {φn(t)} 收敛于 φ(t),且在 t 的任意有限区间的收敛是一致的。
负极限定理:若特征函数列 {φn(t)} 收敛于某一函数 φ(t),且 φ(t) 在 t=0 处连续,则相应的分布函数列 {Fn(x)} 依分布收敛于某一分布函数 F(x),且其特征函数为 φ(t)。
依概率收敛
依概率收敛:对于随机变量列 {ξn},若对于任意 ε>0,有 n→∞limP{∣ξn−ξ∣≥ε}=0
则称 {ξn}
依概率收敛于 ξ,记为 ξn→pξ。
n 足够大时,有非常大的把握认为 ξn 与 ξ 非常接近。
以概率 1 收敛 / 几乎处处收敛
以概率 1 收敛:对于随机变量列 {ξn},若 P(ω:n→∞limξn(ω)=ξ(ω)) (P{n→∞limξn=ξ}=1) 则称 {ξn} 以概率 1 收敛于
ξ,记为 ξn⟶a.s./a.e.ξ。
以概率 1 收敛强于依概率收敛:
设 Ω={ω1,ω2},P{ω1}=P{ω2}=21,ξ(ω1)=1,ξ(ω2)=−1。若 ξn=−ξ,则 ξn 的分布律与 ξ 相同,但 ξn 与 ξ 不以概率 1 收敛。
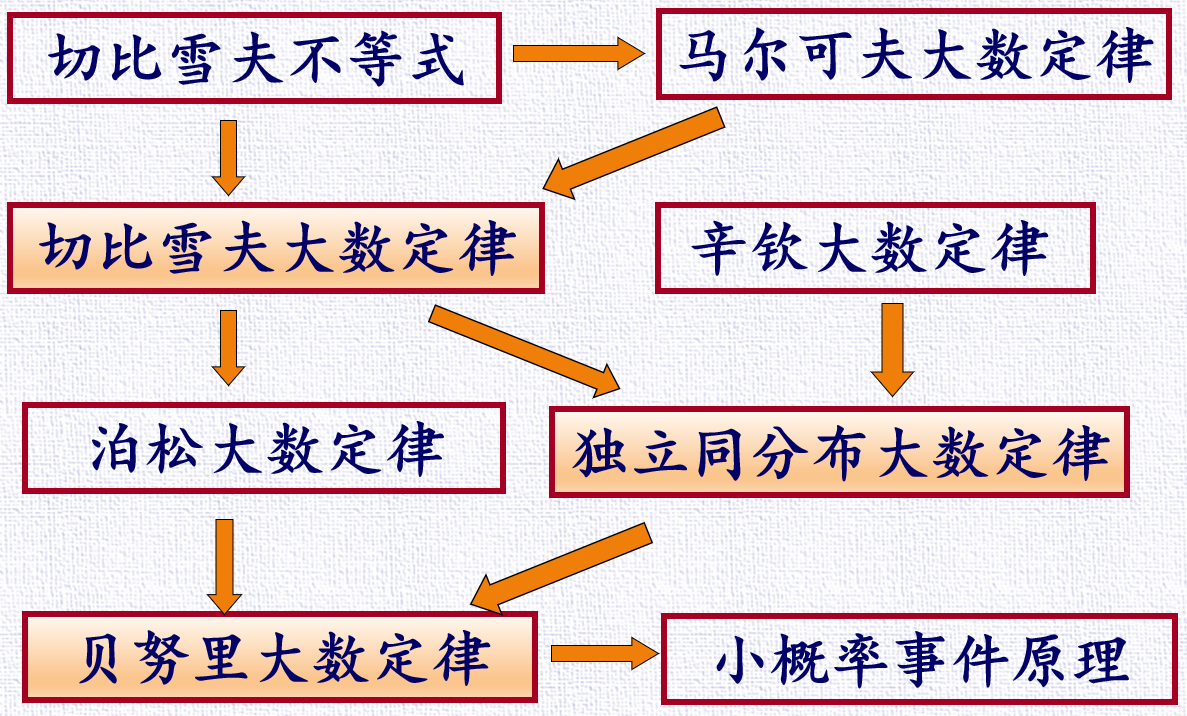
大数定律
弱大数定律
弱大数定律是基于概率收敛的定律。
n1i=1∑nξi−E(ξ)⟶p0
贝努利大数定律:ξ1,ξ2,… 为独立随机变量序列,且
P{ξi=1}=p,P{ξi=0}=1−p(多次独立重复试验的频率紧密地聚集在其概率附近,p=P(A))
小概率事件原理:概率很小的事件,在一次试验中几乎是不可能发生的,从而在实际中可看成不可能事件
泊松大数定律:ξ1,ξ2,… 为独立随机变量序列且
P{ξi=1}=pn,P{ξi=0}=1−pn
独立同分布大数定律:ξ1,ξ2,…
为独立同分布随机变量序列,且均值方差存在
切比雪夫大数定律:多个独立,期望存在,方差一致有界的随机变量的算术平均会紧密地聚集在其期望附近。(设
ξ1,ξ2,…
为期望方差均存在的独立随机变量序列,且方差一致有界,即存在常数 C 使得 D(ξi)≤C )
马尔可夫大数定律:随机变量序列 ξ1,ξ2,… (无需独立)满足 n→∞limn21D(i=1∑nξi)=0
辛钦大数定律:ξ1,ξ2,…
为独立同分布随机变量序列,且各自的期望存在
计算定积分:要求 J=∫abg(x)dx,令 E(g(ξ))=b−a1J,取独立且服从 U[a,b] 的随机变量序列 ξ1,ξ2,…,则 n1∑i=1ng(ξi)→pE(g(ξ))。
用切比雪夫不等式证明切比雪夫大数定律:
P{∣n1∑i=1nξi−n1∑i=1nE(ξi)∣≥ε}≤ε2D(n1∑i=1nξi)=n2ε2D(∑i=1nξi)≤n2ε2nC→0
强大数定律
强大数定律是基于几乎处处收敛性的定律。
n1i=1∑nξi−n1i=1∑nE(ξi)⟶a.s.0
波雷尔大数定律:ξ1,ξ2,…
为独立同分布随机变量序列,且分布律为 P{ξi=1}=p,P{ξi=0}=1−p
(似乎和贝努利大数定律一样)
科尔莫哥洛夫判别法:ξ1,ξ2,…
为独立同分布随机变量序列,且 n=1∑∞n21D(ξn)<+∞
科尔莫哥洛夫定理:ξ1,ξ2,…
为独立同分布随机变量序列,且 E(∣ξk∣)<+∞
中心极限定理
ξ1,ξ2,…
为独立随机变量序列,且存在有限的期望和方差。若随机变量序列 ηn∗=∑i=1nD(ξi)∑i=1nξi−∑i=1nE(ξi) 对 z∈R 一致地有 n→∞limP{ηn∗≤z}=Φ(z) 则称 ξ1,ξ2,… 满足中心极限定理。
即:随机变量序列的前 n
项和的标准化随机变量序列依分布收敛于标准正态分布。
独立同分布中心极限定理
ξ1,ξ2,…
为独立同分布随机变量序列,且 E(ξi)=μ,D(ξi)=σ2,则此随机变量序列满足中心极限定理。
TODO: 林德伯格定理、李雅普诺夫定理
近似计算
若序列 ξ1,ξ2,…
满足中心极限定理,则对于 n
足够大可以认为 ∑i=1nD(ξi)∑i=1nξi−∑i=1nE(ξi)∼N(0,1)
由两点分布的独立同分布中心极限定理,可以得知当 n
足够大时,二项分布的近似计算可以使用正态分布。一般来说,当 np>5,np(1−p)>5
时,可以使用正态分布进行近似计算。
数理统计
基本概念
总体:研究对象的单位元素所组成的集合
个体:组成总体的每个单位元素
样本:按一定的规则从总体中抽取的部分个体(简单随机样本:相互独立且与总体同分布的样本,简称样本)
抽样:从总体中抽取样本的过程
统计量:为随机变量且不含未知参数 的 样本的函数,大写
统计值:样本值代入统计量中得到的具体数值,小写
顺序统计量:样本中的个体按大小排列后的统计量(注意排序破坏了样本间的独立性)
ξ(k)=ξ(k)(ξ1,ξ2,…,ξn) 满足一个样本观测值中 x(1)≤x(2)≤…≤x(n)
总体是随机变量 ξ,样本是一组随机变量 ξ1,ξ2,…,ξn,样本观测值是一组具体数值
x1,x2,…,xn,统计量是样本的函数
T=T(ξ1,ξ2,…,ξn),统计值是样本观测值代入统计量得到的具体数值 t=T(x1,x2,…,xn)。
常见统计量
样本均值:ξ=n1∑i=1nξi=A1
样本方差:S2=n1∑i=1n(ξi−ξ)2=B2
修正样本方差:S∗2=n−11∑i=1n(ξi−ξ)2
样本 k 阶原点矩:Ak=n1∑i=1nξik
样本 k 阶中心矩:Bk=n1∑i=1n(ξi−ξ)k
样本协方差:S12=n1∑i=1n(ξi−ξ)(ηi−η)(二维总体 (ξ,η) 的样本)
样本中位数:M=ξ(2n+1)(奇数)或 21(ξ(2n)+ξ(2n+1))(偶数)
样本极差:Dn∗=ξ(n)−ξ(1)
样本xxx都是随机变量,总体xxx都是常数!
常见统计分布
不会真的有人记得住这些东西的分布律吧……
卡方分布 χ2(n)
设 ξ1,ξ2,…,ξn 为
n 个相互独立的标准正态分布随机变量,则
χ2=i=1∑nξi2∼χ2(n) 服从自由度为 n 的卡方分布。
数字特征:χ2∼χ2(n)⟶E(χ2)=n,D(χ2)=2n
可加性:η1∼χ2(n1),η2∼χ2(n2),则 η1+η2∼χ2(n1+n2)。
大样本近似:unimplemented
t 分布 t(n)
设 ξ∼N(0,1),η∼χ2(n),则 T=η/nξ∼t(n) 服从自由度为 n 的 t 分布。
关于纵轴对称
n 较大时,t
分布近似正态分布
F 分布 F(n1,n2)
设 ξ1∼χ2(n1),ξ2∼χ2(n2),则 F=ξ2/n2ξ1/n1∼F(n1,n2) 服从自由度为 n1,n2 的 F 分布。
F∼F(n1,n2)⇒F1∼F(n2,n1)
F∼F(n1,n2)⇒F1−α(n1,n2)=Fα(n2,n1)1
抽样分布定理
单正态总体
ξ1,ξ2,…,ξn
为来自总体 ξ∼N(a,σ2) 的一个样本,ξ 为样本均值,S2 为样本方差,则有:
ξ 与 S2 独立
σ/nξ−a∼N(0,1)
σ2nS2∼χ2(n−1)
S/n−1ξ−a∼t(n−1)
双正态总体
总体 ξ∼N(a1,σ12),η∼N(a2,σ22),样本均值与样本方差分别为 ξ,S12;η,S22,两总体相互独立。
F=S2∗2/σ22S1∗2/σ12∼F(n1−1,n2−1)
当 σ12=σ22=σ2 时,T=Swn11+n21(ξ−η)−(a1−a2)∼t(n1+n2−2) 其中 Sw2=n1+n2−2n1S12+n2S22
ξ+η∼N(a1+a2,n1σ2+n2σ2)⇒U=σn11+n21ξ+η−a1−a2∼N(0,1)
V=σ2n1S12+σ2n2S22∼χ2(n1+n2−2)
参数估计
设总体 ξ 的分布函数为 F(x;θ),其中 θ 为未知参数,其取值范围 Ω 称为参数空间。
点估计
按照一定的优化原则,建立一个统计量 T,将其统计值 t 作为参数 θ 的估计值,θ^ 称为参数 θ 的点估计量。
θ^=T(ξ1,ξ2,…,ξn)
矩估计法
用样本矩代替总体矩(如:样本均值代替总体均值,样本方差代替总体方差)。
极大似然估计法
得到观测值后,选取 θ^(x1,…,xn) 作为参数 θ 的估计值,使得当 θ 取 θ^
时,样本观测值出现的概率最大。
似然函数:L(x1,x2,…,xn;θ^)=θ∈ΩmaxL(x1,x2,…,xn;θ)
一般解法:
构造似然函数
对似然函数取对数
令 ∂θi∂lnL=0
并非所有极大似然法都遵循一般步骤(如均匀分布总体的区间端点估计)
TODO
估计量的优良性准则
无偏性:E(θ^)=θ(渐进无偏性:n→∞limE(θ^−θ)=0)
修正样本方差 S∗2
是无偏估计量,样本方差 S2
是有偏估计量;但在已知总体均值的情况下,n1∑i=1n(ξi−μ)2 是无偏估计量。
即使 θ^ 是 θ 的无偏估计量,g(θ^) 也不一定是 g(θ) 的无偏估计量。
有效性:D(θ^) 尽可能小
相合性:估计量随样本容量趋于无穷时依概率(以概率
1)收敛到参数的真实值(样本数量足够大时,估计量稳定于真实值)
n→∞limP{∣θ^−θ∣<ε}=1
(弱相合估计量)
P{n→∞limθ^=θ}=1
(强相合估计量)
一些估计量:
无偏估计量:满足无偏性
最小方差无偏估计量:满足无偏性且方差最小(简称最优无偏估计量)
最小方差线性无偏估计量:满足无偏性且方差最小且是线性的(是样本的线性函数)
最小均方误差估计量:满足均方误差(E((θ^−θ)2))最小
无偏估计量 θ^ 为 θ 的最优无偏估计量 ⇔ 对任何无偏估计量 T0 都有 E(θ^⋅T0)=0。
结论:若 θ
为正态总体,则样本均值 ξ
是 θ
的最优无偏估计量,修正样本方差 S∗2 是 θ
的最优无偏估计量。
区间估计,正态总体的枢轴变量法
对于参数 θ,给出一个区间 [T1,T2],使得
P{θ∈[T1,T2]}=1−α,则称 [T1,T2] 为
θ 的置信区间,1−α 为置信度(置信水平),α 为显著性水平。
正态总体的枢轴变量法:
选取待估计参数的估计量 θ^ (原则:优良性准则,常用:ξ→μ,S∗2→σ2)
构造枢轴变量 W(ξ1,ξ2,…,ξn;θ^,θ)
且不包含未知参数
使 W
具有经典分布(如:标准正态分布、t 分布、卡方分布、F 分布)
根据置信水平查上侧分位数,使得 P{w1−α/2≤W≤wα/2}=1−α
改写得到 P{T1≤θ≤T2}=1−α
TODO(!!!)
假设检验
提出统计假设,
根据小概率事件原理用类似反证法的思想对其进行检验。(带有概率性质的反证法)
分布和独立性的假设检验不考
基本概念
原假设 H0:对总体参数或分布的某种假设,如:H0:μ=114,H0:F(x)=Φ(x;μ,σ2)
备择假设 H1:对原假设的否定,如:H1:μ=114,H1:H1:μ=μ1,…(对于相同的原假设,备择假设可有多种选择)
显著性水平 α:H0 成立时构造的小概率事件的概率
接受域:H0
得以接受时检验统计量的取值范围
拒绝域:H0
被拒绝时检验统计量的取值范围
基本步骤
提出原假设 H0 和备择假设
H1
建立检验统计量:寻找待检验参数的估计量,并据此建立一个不带未知参数的统计量
W
确定 H0 成立时 W 的分布
确定显著性水平 α,并根据
α 查找拒绝域
根据样本数据计算 W 的统计值
w,并根据 w 是否落在拒绝域中决定是否拒绝 H0
如何确定 α:当 α 较小时,拒绝域较小,使得 H0
被接受的概率较大,一般对较为信任的原假设取较小的 α
有利原则:确定 H0
的拒绝域时,应使得对 H1
成立有利的区域作为拒绝域
两类错误
一般先控制弃真错误,再控制纳伪错误
TODO: 检测法
回归分析(概念)
概念
相关关系:变量之间存在联系,但无法用确定的函数来明确描述(如:产品的价格Y与需求量X之间存在关系)
自变量/可控变量:影响因素,用来解释因变量的变化
因变量/被控变量:反映结果,受自变量影响
回归函数:μ(x1,…,xn)=E(Y ∣ X1=x1,…,Xn=xn)(是一个确定的函数,可以理解为在 X=x 的条件下 Y 取值的集中点)
基本思想:通过自变量与因变量的观测值,估计回归函数
回归方程:y=μ(x1,…,xn)
回归模型:Y=μ(X1,…,Xn)+ε,其中 ε
为误差项,通常要求:
E(ε)=0
D(ε)=σ2
尽可能小
最小二乘法:使得残差平方和 Q=∑(yi−yi^)2 最小
相关系数:r=D(X)D(Y)Cov(X,Y)
线性化:将非线性回归模型转化为线性回归模型(例:y=aexp(bx)⇒lny=lna+bx)
无法线性化: